Corriger et identifier les problèmes de Time to First Byte (TTFB)
Découvrez comment déboguer les problèmes de Time to First Byte sur vos pages en utilisant les données RUM, les en-têtes Server-Timing et une analyse systématique des sous-parties du TTFB.

Trouver et corriger les problèmes de Time to First Byte (TTFB)
Cet article fait partie de notre guide sur le Time to First Byte (TTFB). Le TTFB est une métrique de diagnostic qui mesure le temps écoulé entre la requête d'une page par un utilisateur et la réception du premier octet de la réponse par le navigateur. Bien que le TTFB ne soit pas un Core Web Vital en soi, il influence directement à la fois le First Contentful Paint (FCP) et le Largest Contentful Paint (LCP). Un bon TTFB est inférieur à 800 millisecondes au 75e centile.
Dans notre article précédent, nous avons abordé le Time to First Byte. Si vous souhaitez vous familiariser avec les bases, c'est un excellent point de départ.
Dans cet article, nous nous concentrerons sur l'identification des différents problèmes de Time to First Byte et expliquerons ensuite comment les résoudre.
CONSEIL TTFB : la plupart du temps, le TTFB sera bien pire pour les nouveaux visiteurs puisqu'ils ne disposent pas d'un cache DNS pour votre site. Lors du suivi du TTFB, il est très judicieux de faire la distinction entre les nouveaux visiteurs et les visiteurs récurrents.
Table of Contents!
- Trouver et corriger les problèmes de Time to First Byte (TTFB)
- Étape 1 : Vérifier le TTFB dans la Search Console
- Étape 1b : Utiliser l'en-tête Server-Timing pour une analyse plus approfondie
- Étape 2 : Configurer le suivi RUM
- Étape 2b : Établir une base de référence des performances
- Étape 3 : Identifier les problèmes de Time to First Byte
- Étape 4 : Analyser les problèmes en profondeur et les corriger
- Étape 5 : Liste de contrôle des correctifs rapides pour les problèmes courants de TTFB
- Mesurer le TTFB avec JavaScript
- Lectures complémentaires : Guides d'optimisation
- Sous-parties du TTFB : Guides complets
Étape 1 : Vérifier le TTFB dans la Search Console
"La première étape vers la guérison est d'admettre que vous avez un problème." Donc, avant de faire quoi que ce soit pour corriger le Time to First Byte, assurons-nous que nous avons réellement un problème avec le TTFB.
Malheureusement, le Time to First Byte n'est pas signalé dans la Google Search Console, nous devons donc nous rabattre sur pagespeed.web.dev pour interroger les données CrUX de notre site. Heureusement, les étapes sont simples : accédez à pagespeed.web.dev, entrez l'URL de votre page, et assurez-vous que le bouton "origin" est coché (puisque nous avons besoin de données à l'échelle du site et pas seulement pour la page d'accueil). Basculez maintenant entre Mobile et Desktop et vérifiez le Time to First Byte pour les deux types d'appareils.
Dans l'exemple ci-dessous, vous verrez un site qui échoue aux Core Web Vitals en raison d'un TTFB élevé.
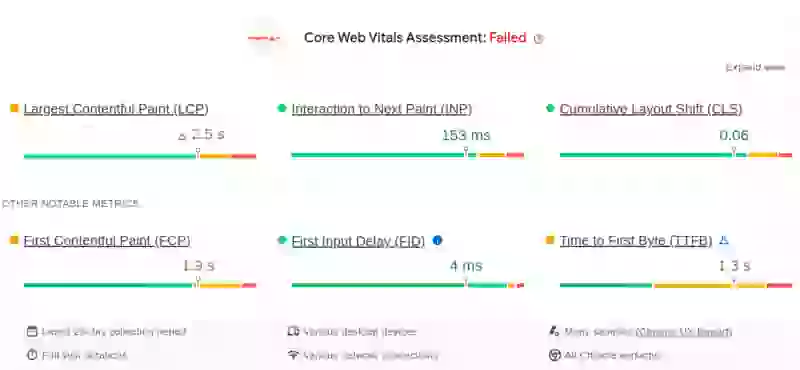
Étape 1b : Utiliser l'en-tête Server-Timing pour une analyse plus approfondie
L'en-tête de réponse HTTP Server-Timing permet à votre serveur de communiquer les métriques de performance du backend directement au navigateur. Cela permet d'identifier précisément quelle partie du traitement serveur est lente sans avoir besoin d'accéder aux journaux du serveur.
Un en-tête Server-Timing typique ressemble à ceci :
Server-Timing: db;dur=53, app;dur=120, cache;desc="miss"
Dans cet exemple, le serveur signale trois valeurs de temps :
- db;dur=53 : la requête à la base de données a pris 53 millisecondes.
- app;dur=120 : la logique de l'application (rendu de modèle, appels API, etc.) a pris 120 millisecondes.
- cache;desc="miss" : le cache du serveur n'a pas été utilisé pour cette requête (un échec de cache).
Vous pouvez lire ces valeurs dans les Chrome DevTools en ouvrant l'onglet Réseau (Network), en sélectionnant la requête du document et en faisant défiler jusqu'à la section "Server Timing" dans l'onglet Timing. Les valeurs sont également accessibles via l'API PerformanceServerTiming en JavaScript :
const [navigation] = performance.getEntriesByType('navigation');
if (navigation.serverTiming) {
navigation.serverTiming.forEach(entry => {
console.log(`${entry.name}: ${entry.duration}ms (${entry.description})`);
});
} Si votre serveur n'envoie pas encore d'en-têtes Server-Timing, envisagez de les ajouter. La plupart des frameworks web rendent cela simple. En PHP, vous pouvez ajouter l'en-tête avant toute sortie :
header('Server-Timing: db;dur=' . $dbTime . ', app;dur=' . $appTime); En Node.js avec Express :
res.setHeader('Server-Timing', `db;dur=${dbTime}, app;dur=${appTime}`); L'en-tête Server-Timing est particulièrement utile lorsqu'il est combiné au Real User Monitoring, car il vous permet de corréler les performances côté serveur avec le TTFB que les utilisateurs réels expérimentent. Découvrez comment le code 103 Early Hints peut réduire encore davantage le TTFB perçu en envoyant des indices de ressources avant que la réponse complète ne soit prête.
Étape 2 : Configurer le suivi RUM
Le Time to First Byte est une métrique complexe. Nous ne pouvons pas simplement nous fier à des tests synthétiques pour mesurer le TTFB, car dans la vie réelle, d'autres facteurs contribueront aux fluctuations du TTFB. Pour obtenir des réponses à toutes les questions ci-dessus, nous devons mesurer les données en conditions réelles et consigner tous les problèmes qui pourraient survenir avec le Time to First Byte. C'est ce qu'on appelle le Real User Monitoring, et il existe plusieurs façons d'activer le suivi RUM. Nous avons développé CoreDash précisément pour ces cas d'utilisation. CoreDash est un outil RUM abordable, rapide et efficace qui fait le travail. Bien sûr, il existe de nombreuses solutions RUM sur le marché et elles feront également l'affaire (à un prix plus élevé cependant).
Comment appréhender le TTFB : Imaginez qu'un serveur web est la cuisine d'un restaurant et qu'un utilisateur demandant une page web est un client affamé passant une commande. Le Time to First Byte (TTFB) est la durée entre le moment où le client passe sa commande et celui où la cuisine commence à préparer la nourriture.
Le TTFB ne concerne donc PAS la vitesse à laquelle l'ensemble du repas est cuisiné (First Contentful Paint) et servi (Largest Contentful Paint), mais plutôt la réactivité de la cuisine à la demande initiale.
Le suivi RUM revient à interroger les clients pour comprendre leur expérience culinaire. Vous pourriez découvrir que les clients assis plus loin de la cuisine reçoivent moins d'attention du serveur et sont servis plus tard, ou que les clients habituels bénéficient d'un traitement de faveur tandis que les nouveaux visiteurs doivent attendre plus longtemps pour obtenir une table.
Étape 2b : Établir une base de référence des performances
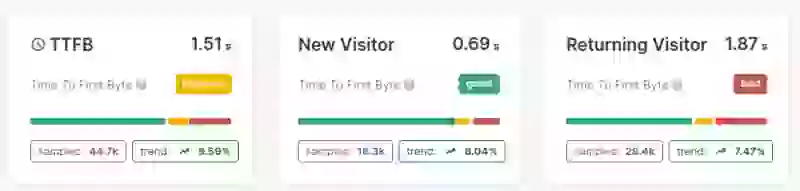
Avant d'apporter des modifications, établissez une base de référence pour votre TTFB. Enregistrez le TTFB au 75e centile sur les dimensions suivantes, car cela vous aidera à mesurer l'efficacité de vos optimisations plus tard :
- TTFB global (mobile et desktop séparément) : capturez le 75e centile pour chaque type d'appareil.
- Top 10 des pages par trafic : enregistrez individuellement le TTFB pour vos pages à plus fort trafic.
- Nouveaux visiteurs vs visiteurs récurrents : les nouveaux visiteurs ont généralement un TTFB plus élevé en raison du DNS et du temps de connexion.
- Top 5 des pays par trafic : la distance géographique par rapport à votre serveur affecte considérablement le TTFB.
- Répartition des sous-parties du TTFB : enregistrez le 75e centile pour chaque sous-partie (attente, cache, DNS, connexion, requête).
Consignez ces chiffres dans une feuille de calcul. Après avoir implémenté chaque optimisation, attendez au moins 7 jours pour collecter suffisamment de données RUM avant de comparer les résultats. Une bonne approche consiste à traiter une sous-partie du TTFB à la fois, à mesurer, puis à passer à la suivante.
Étape 3 : Identifier les problèmes de Time to First Byte
Bien que le Chrome User Experience Report (CrUX) de Google fournisse de précieuses données de terrain, il n'offre pas de détails spécifiques sur les causes d'un TTFB élevé. Pour améliorer efficacement le TTFB, nous devons savoir exactement ce qui se passe à un niveau plus détaillé. À ce stade, il est judicieux de faire la distinction entre un TTFB défaillant de manière globale et un TTFB défaillant dans des conditions spécifiques (bien qu'en réalité, il y aura toujours un mélange des deux).
3.1 Le TTFB échoue de manière globale
- Vérifier la présence de "temps de requête" (request times) généralement médiocres : Des temps de requête médiocres signifient que le "problème" vient du temps qu'il faut au serveur pour générer la page. C'est la cause la plus courante des mauvais scores de TTFB.
- Vérifier les autres sous-parties médiocres du TTFB : Le TTFB n'est pas seulement une métrique unique, mais il peut être décomposé en plusieurs parties qui ont chacune leur propre potentiel d'optimisation. Si la durée d'attente (waiting duration), la durée de cache (cache duration), la durée de résolution DNS (DNS lookup duration) ou la durée de connexion (connection duration) sont lentes, vous devrez probablement ajuster les paramètres de votre serveur ou commencer à chercher un hébergement de meilleure qualité.
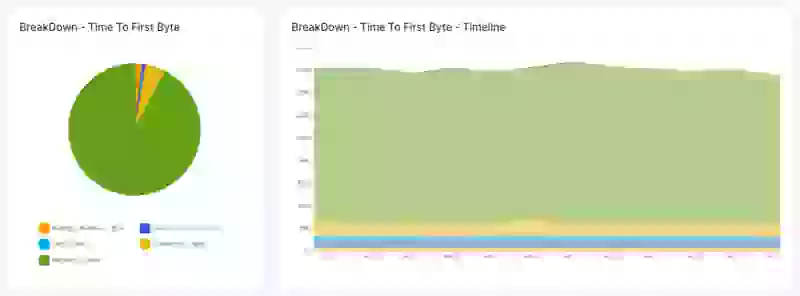
3.2 Le TTFB échoue dans des conditions spécifiques
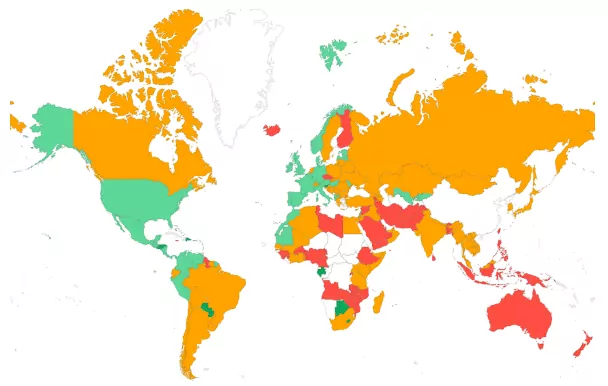
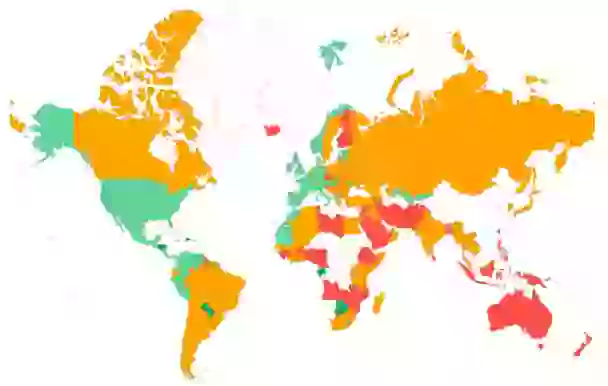
- Segmentation par pays : Comprendre la distribution géographique d'un TTFB élevé est important, surtout pour les sites web ayant une audience mondiale. Si vous servez vos pages depuis un seul serveur dans un seul pays (sans mise en cache périphérique de CDN), la distance physique entre l'emplacement de l'utilisateur et le serveur hébergeant le site web causera toutes sortes de retards et impactera le TTFB. Envisagez de configurer Cloudflare ou un autre CDN pour rapprocher votre contenu des utilisateurs du monde entier.
- Segmentation du cache : La mise en cache peut réduire le TTFB en ignorant la génération côté serveur du HTML. Malheureusement, il est courant que la mise en cache soit désactivée ou contournée pour de nombreuses raisons. Par exemple, la mise en cache peut être désactivée pour les utilisateurs connectés, les pages de panier d'achat, les pages avec des chaînes de requête (par exemple, de Google Ads), les pages de résultats de recherche et les pages de paiement. Si votre site web utilise la mise en cache (en périphérie), utilisez le suivi RUM pour vérifier le taux de réussite du cache.
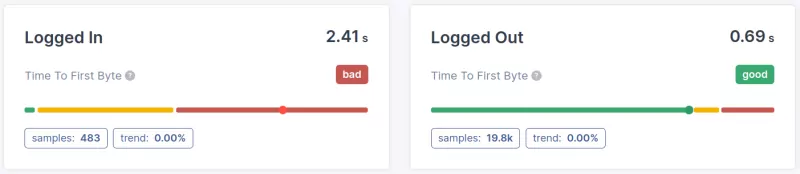
- Segmentation par page (cluster) : La différence de performance du Time to First Byte (ou l'absence de différence) entre les pages ou les types de pages est une autre chose que nous devons déterminer. Savoir quelles pages échouent à la métrique TTFB fournira des informations précieuses sur la façon d'améliorer le Time to First Byte.

- Segmentation des redirections : Le temps de redirection s'ajoute directement au TTFB. Chaque redirection ajoute du temps supplémentaire avant que le serveur web ne puisse commencer à charger la page. Mesurer et éliminer les redirections inutiles peut aider à améliorer le TTFB. Pour un aperçu plus approfondi de l'optimisation des redirections, consultez notre guide sur la sous-partie durée d'attente (waiting duration) du TTFB.

- Autre segmentation : Bien que la segmentation par les variables ci-dessus couvre les suspects habituels, chaque site est unique et possède ses propres défis. Heureusement, le suivi RUM est conçu pour permettre une segmentation par de nombreuses autres variables telles que la RAM de l'appareil, la vitesse du réseau, le type d'appareil, le système d'exploitation, des variables personnalisées, et bien plus encore.
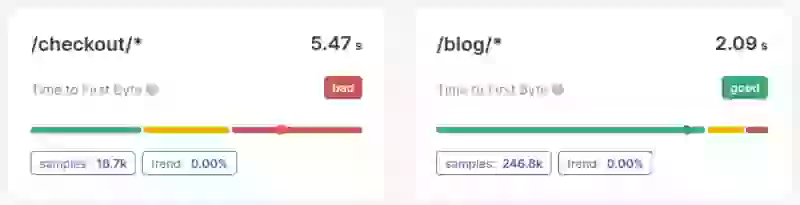

Étape 4 : Analyser les problèmes en profondeur et les corriger
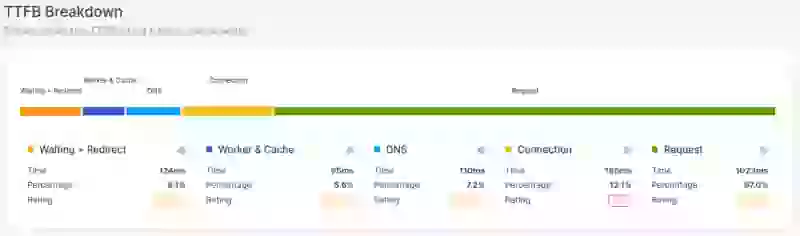
Les sous-parties du Time to First Byte (TTFB) sont :
- Attente + Redirection (ou durée d'attente)
- Worker + Cache (ou durée de cache)
- DNS (ou durée DNS)
- Connexion (ou durée de connexion)
- Requête (ou durée de requête)
Étape 5 : Liste de contrôle des correctifs rapides pour les problèmes courants de TTFB
En fonction de la sous-partie qui contribue le plus à votre TTFB, voici une référence rapide pour les correctifs les plus courants :
| Sous-partie du TTFB | Cause la plus courante | Correctif rapide |
|---|---|---|
| Durée d'attente | Redirections inutiles | Auditer et éliminer les chaînes de redirection ; implémenter HSTS |
| Durée de cache | Démarrage lent du service worker | Simplifier le code du service worker ; utiliser des stratégies de mise en cache efficaces |
| Durée DNS | Fournisseur DNS lent | Passer à un fournisseur DNS premium comme Cloudflare ; ajuster les paramètres TTL |
| Durée de connexion | Version TLS obsolète | Activer TLS 1.3 et HTTP/3 ; utiliser un CDN pour la proximité |
| Durée de requête | Traitement lent du serveur | Implémenter la mise en cache côté serveur ; optimiser les requêtes à la base de données ; utiliser les 103 Early Hints |
Mesurer le TTFB avec JavaScript
Vous pouvez mesurer le TTFB complet et ses sous-parties directement dans le navigateur en utilisant l'API Navigation Timing. L'extrait suivant calcule le TTFB et consigne chaque sous-partie :
new PerformanceObserver((entryList) => {
const [nav] = entryList.getEntriesByType('navigation');
const activationStart = nav.activationStart || 0;
const ttfb = nav.responseStart - activationStart;
const waitingDuration = (nav.workerStart || nav.fetchStart) - activationStart;
const cacheDuration = nav.domainLookupStart - (nav.workerStart || nav.fetchStart);
const dnsDuration = nav.domainLookupEnd - nav.domainLookupStart;
const connectionDuration = nav.connectEnd - nav.connectStart;
const requestDuration = nav.responseStart - nav.requestStart;
console.log('TTFB:', ttfb.toFixed(0), 'ms');
console.log(' Waiting:', waitingDuration.toFixed(0), 'ms');
console.log(' Cache:', cacheDuration.toFixed(0), 'ms');
console.log(' DNS:', dnsDuration.toFixed(0), 'ms');
console.log(' Connection:', connectionDuration.toFixed(0), 'ms');
console.log(' Request:', requestDuration.toFixed(0), 'ms');
}).observe({
type: 'navigation',
buffered: true
}); Ce code fournit la même répartition que celle affichée par des outils comme CoreDash dans le panneau d'attribution du TTFB. L'exécution de cet extrait dans la console du navigateur vous donne une lecture immédiate pour le chargement d'une seule page, tandis que les outils RUM collectent ces données sur des milliers d'utilisateurs réels pour produire des valeurs fiables au 75e centile.
Lectures complémentaires : Guides d'optimisation
Guides connexes :
- 103 Early Hints : envoyez des indices de ressources avant que la réponse complète ne soit prête, ce qui permet au navigateur de commencer à charger les ressources critiques pendant que le serveur est encore en train de traiter la demande.
- Configurer Cloudflare pour les performances : configurez le CDN, la mise en cache et les fonctionnalités périphériques de Cloudflare pour réduire le TTFB pour les audiences mondiales.
Sous-parties du TTFB : Guides complets
Chaque sous-partie du Time to First Byte a ses propres stratégies d'optimisation. Commencez par la sous-partie que vos données RUM identifient comme étant le goulot d'étranglement :
- Durée d'attente (Waiting Duration) : redirections, mise en file d'attente du navigateur et optimisation HSTS.
- Durée de cache (Cache Duration) : performances du service worker, cache du navigateur et bfcache.
- Durée DNS (DNS Duration) : sélection du fournisseur DNS, configuration du TTL et dns-prefetch.
- Durée de connexion (Connection Duration) : handshake TCP, optimisation TLS, HTTP/3 et preconnect.
- Durée de requête (Request Duration) : temps de traitement du serveur, requêtes de base de données et optimisation du backend.
Je fais passer les sites aux Core Web Vitals.
500K+ pages chez les grands éditeurs européens et les plateformes e-commerce. J'écris les fix moi-même et je les vérifie avec vos données terrain.
Ma méthode
