Åtgärda & identifiera problem med Largest Contentful Paint (LCP)
Lär dig felsöka och åtgärda alla problem relaterade till Largest Contentful Paint på din sida

En konsults guide till att diagnostisera och åtgärda LCP
Mitt namn är Arjen Karel, och jag är konsult inom sidladdningshastighet. Under åren har jag granskat hundratals webbplatser, och en av de mest ihållande utmaningarna är Largest Contentful Paint (LCP). I denna guide delar jag den exakta metodik jag använder för att diagnostisera och lösa LCP-problem. Du kommer att se omnämnanden av CoreDash, ett RUM-verktyg jag skapade för att få den precisa data som behövs för denna process. Principerna här är universella, men jag tror på att visa verkliga exempel från de verktyg jag bygger och använder dagligen.
Att förbättra LCP är en systematisk elimineringsprocess. Genom att följa en tydlig metodik kan du effektivt diagnostisera flaskhalsarna i din sidladdningsprocess och tillämpa riktade åtgärder för att förbättra din webbplats prestanda och user experience.
Diagnostikmetodiken: fältdata först, labbdata sedan
För att optimera effektivt måste du använda ett tvåstegs diagnostiskt arbetsflöde. Detta säkerställer att du löser problem som dina användare faktiskt upplever, inte bara jagar poäng i en labbmiljö.
- Fältdata (RUM & CrUX) visar dig VAD som händer. Fältdata samlas in från riktiga användare som besöker din webbplats [1]. Det berättar om du har ett LCP-problem, vilka sidor som påverkas, och vilka användare (mobil eller desktop) som upplever det. Du måste alltid börja här för att bekräfta att ett verkligt problem existerar.
- Labbdata (Lighthouse, DevTools) hjälper dig diagnostisera VARFÖR det händer. Labbdata samlas in i en kontrollerad, simulerad miljö [2]. När din fältdata har bekräftat ett problem på en specifik sida kan du använda labbverktyg för att konsekvent replikera problemet och dissekera laddningsprocessen för att hitta grundorsaken.
Att börja med fältdata säkerställer att dina optimeringsinsatser fokuseras på ändringar som kommer ha en mätbar påverkan på dina faktiska användare.
Table of Contents!
Nyckelterminologi
- Fältdata: Även känt som Real User Monitoring (RUM), detta är prestandadata insamlad från faktiska användare under varierande, verkliga förhållanden (olika enheter, nätverkshastigheter och platser).
- Labbdata: Prestandadata insamlad i en kontrollerad, konsekvent miljö med verktyg som Lighthouse. Det är idealiskt för felsökning och testning av ändringar, men speglar inte alltid den verkliga användarupplevelsen.
- CrUX: Chrome User Experience Report. En offentlig datamängd från Google som innehåller fältdata från miljontals Chrome-användare. Den driver Core Web Vitals-rapporten i Google Search Console.
- TTFB (Time to First Byte): Tiden mellan att webbläsaren begär en sida och när den tar emot den allra första byten av HTML-svaret. Det är ett mått på serverns svarstid.
Steg 1: Identifiera LCP-problem med fältdata
Din första uppgift är att använda data från riktiga användare för att bekräfta vilka sidor, om några, som har dåligt LCP.
En tillgänglig startpunkt: Google Search Console
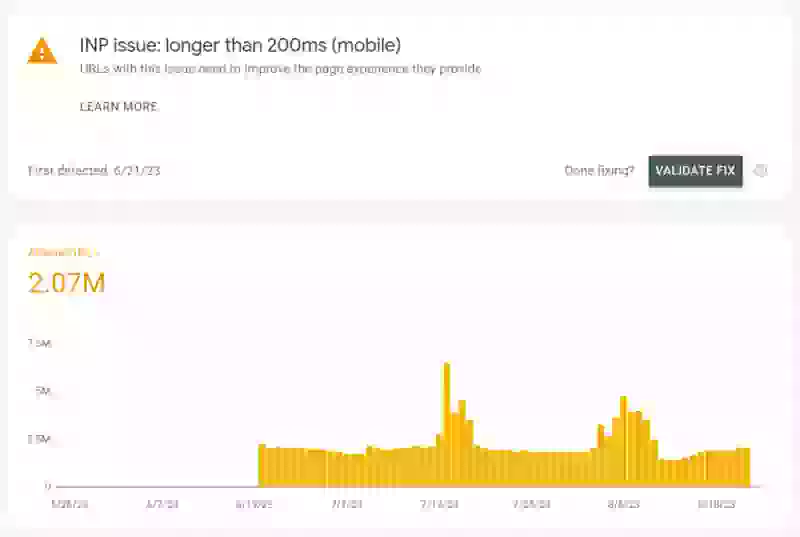
En bra plats att börja är rapporten Core Web Vitals i Google Search Console. Logga in, navigera till rapporten och granska diagrammen för mobil och desktop. Om Google flaggar URL:er med "LCP issue: longer than 2.5s" har du bekräftelse från Chrome User Experience (CrUX) Report att en andel av dina användare har en dålig upplevelse.
Även om Search Console är ovärderligt för att bekräfta ett problem, är det långsamt att uppdatera och grupperar data efter URL-mönster. För mer omedelbara och detaljerade insikter krävs ett dedikerat RUM-verktyg.
En djupare titt: Real User Monitoring (RUM)
För att få den verkliga bilden kan du spåra LCP för varje användare vid varje sidladdning med en Real User Monitoring (RUM)-lösning. Du kan bygga din egen genom att använda web-vitals-biblioteket för att skicka data till din analysbackend, men detta kan vara en betydande teknisk insats.
Alternativt är dedikerade RUM-verktyg utformade för detta ändamål. Verktyg som CoreDash är byggda för att tillhandahålla denna data direkt. Att konfigurera det innebär vanligtvis att lägga till ett litet JavaScript-kodsnutt i din webbplats header. När det är installerat börjar det samla in prestandadata från varje riktig besökare.
Ett bra RUM-verktyg hjälper dig gå bortom URL-grupper för att förstå:
- Ditt exakta LCP-resultat för en specifik URL.
- En uppdelning av varje LCP-element (t.ex. en bild, en rubrik) och vilka som oftast är associerade med ett långsamt LCP.
- Den exakta tidpunkten för var och en av de fyra LCP-faserna för varje sidvisning, som pekar ut flaskhalsen.
Vid en nyligen genomförd granskning för en e-handelskund såg vi höga LCP-värden på produktsidor trots en fullt optimerad hero-bild. Vår RUM-data avslöjade att fördröjningen inte var bilden i sig, utan ett klientbaserat A/B-testskript som dynamiskt ändrade produkttiteln, som var LCP-elementet. Detta skript blockerade renderingen tillräckligt länge för att driva LCP in i kategorin "dåligt". Att pausa testet löste problemet omedelbart, vilket bevisar att LCP-optimering kräver att man ser bortom bara LCP-elementet i sig.
Till exempel kan du i CoreDash navigera till LCP-sidan och visa en datatabell som visar dina långsammaste LCP-element. Genom att klicka på ett specifikt element (som en viss CSS-klass för en hero-bild) kan du filtrera alla mätvärden för att se prestandadata enbart för sidor där det elementet var LCP.
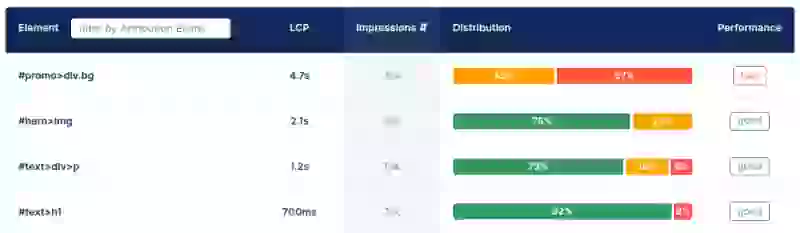
Oavsett om du använder en anpassad lösning eller ett verktyg som CoreDash är målet detsamma: använd fältdata för att hitta din långsammaste sida och identifiera dess vanligaste LCP-element. När du har det målet är du redo att diagnostisera.
Steg 2: Diagnostisera flaskhalsen med labbverktyg
Nu vet du vilken sida du ska åtgärda, och det är dags att ta reda på varför den är långsam. Det är här ett labbverktyg som PageSpeed Insights eller Lighthouse-panelen i Chrome DevTools blir avgörande [3].
Kör ett test på din mål-URL. I rapporten, scrolla ner till avsnittet "Diagnostics" och hitta granskningen "Largest Contentful Paint element". Detta vattenfallsdiagram bryter ner din LCP-tid i dess fyra deldelar. Ditt RUM-verktyg bör visa en liknande uppdelning baserad på din fältdata.
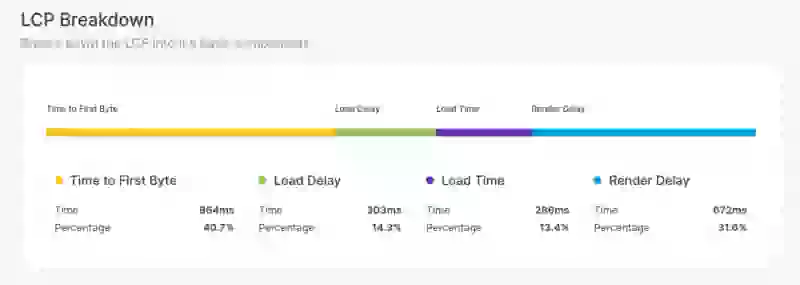
Ditt mål är att hitta den längsta fasen i denna uppdelning. Det är din primära flaskhals, och det är där du bör fokusera dina optimeringsinsatser först.
Steg 3: Förstå den verkliga flaskhalsen
I de flesta verkliga scenarier kommer de mest betydande och ihållande LCP-problemen från en av de andra tre faserna.
- Time to First Byte (TTFB): Detta är den oundvikliga grunden. En långsam server- respons är ett direkt, millisekund-för-millisekund-tillägg till ditt LCP. Innan du optimerar en enda bild måste du säkerställa att din server svarar snabbt.
- Resource Load Delay: Detta är "upptäcktsproblemet" och ett av de vanligaste problemen. Webbläsaren kan inte ladda ner en resurs den inte känner till. Om din LCP-bild är gömd i en CSS- eller JavaScript-fil, eller även om den finns i HTML men andra resurser begärs först, hittar webbläsaren den för sent och slösar värdefull tid.
- Element Render Delay: Detta är problemet "för upptagen för att rendera". LCP-bildfilen kan vara helt nedladdad, men om webbläsarens huvudtråd är blockerad av tung JavaScript- exekvering kan den helt enkelt inte komma till att rita bilden på skärmen.
Följande guide är strukturerad för att hantera dessa faser i en logisk ordning. Börja alltid med att säkerställa att din TTFB är snabb och din LCP-resurs är upptäckbar innan du går vidare till filstorlek- och render- optimeringar.
Steg 4: Genomför åtgärden
Med flaskhalsen identifierad kan du tillämpa riktade optimeringar. Sättet du implementerar dessa åtgärder beror mycket på din webbplats arkitektur. Vi täcker först de universella principerna för varje fas, sedan ger vi specifika råd för WordPress och moderna JavaScript-ramverk.
1. Optimera Time to First Byte (TTFB)
Om din TTFB är långsam (ett bra mål är under 800 ms [4]) sätter det en hög lägstanivå för ditt LCP. Att förbättra TTFB förbättrar alla andra laddningsmätvärden. Detta är tiden det tar för webbläsaren att ta emot den första byten av HTML från din server.

Universella TTFB-lösningar
- Aktivera caching: Detta är ett av de mest effektiva sätten att förbättra TTFB. Caching genererar och lagrar en kopia av sidan så att den kan levereras omedelbart utan att vänta på att servern bygger den från grunden vid varje besök.
- Använd en CDN: Ett Content Delivery Network levererar ditt innehåll från en server fysiskt nära din användare, vilket minskar nätverksfördröjningen [5]. Att cacha dina fullständiga HTML-sidor vid CDN:ens edge är en kraftfull strategi för snabb, global TTFB.
- Använd Brotli- eller Gzip-komprimering: Säkerställ att din server komprimerar textbaserade resurser som HTML, CSS och JavaScript. Brotli erbjuder bättre komprimering än Gzip och bör föredras.
- Använd HTTP/3 med 0-RTT: Säkerställ att din server är konfigurerad att använda HTTP/3. Det erbjuder betydande prestandafördelar, inklusive bättre multiplexering. Avgörande är att det stöder 0-RTT (Zero Round Trip Time Resumption), som eliminerar anslutningstiden för återkommande besökare och ger en omedelbar TTFB-förbättring [6].
- Använd 103 Early Hints: För en avancerad förbättring, använd statuskoden 103 Early Hints. Detta gör det möjligt för din server eller CDN att skicka ledtrådar om kritiska CSS- och JS-filer till webbläsaren medan den fortfarande förbereder det fullständiga HTML-dokumentet, vilket låter nedladdningar starta ännu tidigare [7]. Detta är en kraftfull funktion på servernivå som kan gynna alla plattformar.
Plattformsspecifika TTFB-åtgärder
På WordPress:
- Investera i kvalitetshosting: På WordPress är långsam TTFB ofta relaterad till hostingmiljön. Billig, delad hosting kan vara en flaskhals. Överväg en managed WordPress- hosting som är optimerad för prestanda.
- Använd en cachingplugin: En cachingplugin av hög kvalitet (t.ex. WP Rocket, W3 Total Cache) är oumbärlig. Den hanterar genereringen av statiska HTML-filer åt dig, vilket är kärnan i effektiv caching på denna plattform.
På ett JS-ramverk:
- Välj rätt hostingplattform: För Node.js-applikationer är plattformar som Vercel eller Netlify högt optimerade för SSR/SSG-ramverk och erbjuder intelligent caching och serverlös funktionsexekvering direkt.
- Implementera SSR-caching: Om du använder Server-Side Rendering, cacha de renderade sidorna på servern (t.ex. med Redis eller en in-memory-cache) för att undvika omrendering vid varje begäran.
- Se upp för serverlösa kallstarter: Om du använder serverlösa funktioner för rendering, var medveten om att en "cold start" (den första begäran efter en period av inaktivitet) kan ha hög TTFB. Använd provisioned concurrency eller keep-alive-strategier för att mildra detta.
2. Minska Resource Load Delay
Detta är ofta den största flaskhalsen. Det innebär att webbläsaren var redo att arbeta, men den kunde inte hitta din huvudbild eller teckensnittsfil direkt. Denna fördröjning orsakas vanligtvis av ett av två problem: resursen upptäcks sent, eller den ges låg nedladdningsprioritet.

Universella lösningar för Load Delay
Den universella lösningen för Resource Load Delay är att säkerställa att din LCP-resurs både är upptäckbar i den initiala HTML-koden och ges hög prioritet av webbläsaren. Så här uppnår du det:
- Gör LCP-resursen upptäckbar: Det viktigaste steget är att säkerställa att ditt LCP-element finns i den HTML som servern skickar. Webbläsare använder en höghastighets-"preload scanner" för att söka igenom rå HTML efter resurser som bilder och skript att ladda ner. Om din LCP-bild laddas via en CSS `background-image` eller injiceras med JavaScript är den osynlig för denna scanner, vilket orsakar en stor fördröjning. Den mest robusta lösningen är alltid att använda en standard
<img>-tagg med ett `src`-attribut i din serverrenderade HTML. - Kontrollera laddningsordningen med `preload`: Om du inte kan göra LCP-resursen direkt upptäckbar (ett vanligt problem med teckensnitt eller CSS-bakgrundsbilder) är nästa bästa lösning att använda
<link rel="preload">. Denna tagg fungerar som en explicit instruktion i din HTML<head>, som talar om för webbläsaren att börja ladda ner en kritisk resurs mycket tidigare än den skulle ha hittat den naturligt. Detta är väsentligt för att ändra den absoluta laddningsordningen, och säkerställa att din LCP-bild eller teckensnitt köas före mindre kritiska resurser som asynkrona JavaScript-filer. - Säkerställ hög prioritet med `fetchpriority`: Även när en resurs är upptäckbar kanske webbläsaren inte ger den högsta nedladdningsprioriteten. Att lägga till
fetchpriority="high"till din<img>-tagg eller din<link rel="preload">-tagg är en kraftfull ledtråd till webbläsaren att denna specifika resurs är den viktigaste för user experience, och hjälper den vinna kampen om bandbredd mot andra resurser [8].
Plattformsspecifika åtgärder för Load Delay
På WordPress:
- Undvik bakgrundsbilder från sidbyggare: Många sidbyggare gör det enkelt att ställa in en hero-bild som en CSS `background-image` på en `div`. Detta gör den osynlig för webbläsarens preload scanner. Om möjligt, använd ett standard `
`-block istället. Om inte, kan du behöva en plugin eller anpassad kod för att `preloada` den specifika bilden.
- Inaktivera lazy-loading för LCP-bilden: Många optimeringsplugins kommer automatiskt att lazy-loada alla bilder. Du måste hitta inställningen i din plugin för att exkludera LCP-bilden (och ofta de första bilderna på sidan) från att lazy-loadas.
På ett JS-ramverk:
- Använd Server-Side Rendering (SSR): Detta är ofta den mest genomgripande åtgärden. En standard Client-Side Rendered (CSR) React-app skickar minimal HTML, och LCP-elementet existerar bara efter att ett stort JS-paket har laddats ner och exekverats. SSR-ramverk som Next.js eller Remix levererar fullständig HTML, inklusive `
`-taggen, så webbläsaren kan upptäcka den omedelbart.
- Använd ramverksspecifika bildkomponenter: Ramverk som Next.js erbjuder en `
`-komponent med en `priority`-prop. Att använda `
` tillämpar automatiskt `fetchpriority="high"` och andra optimeringar på din LCP-bild.
3. Minska Resource Load Time
Att säkerställa att din LCP-resurs är så liten som möjligt är fortfarande en avgörande del av processen. Denna fas handlar om hur lång tid det tar att ladda ner LCP-resursfilen över nätverket.

Universella lösningar för Load Time
- Minska filstorleken med moderna format och responsiva bilder: Det mest direkta sättet att förkorta nedladdningstiden är att göra filen mindre. För bilder innebär detta att använda moderna, högt effektiva format som AVIF eller WebP [9]. Avgörande är att du också måste leverera responsiva bilder med
<picture>-elementet eller attributensrcsetochsizes. Detta säkerställer att en användare på en mobil enhet får en bild anpassad för sin mindre skärm, istället för att tvingas ladda ner en massiv desktopanpassad bildfil. En 400 pixlar bred mobilskärm behöver helt enkelt inte en 2000 pixlar bred bildfil. För textbaserade LCP, säkerställ att dina teckensnitt är i det effektiva WOFF2-formatet och är subsettade för att ta bort oanvända tecken. - Minska nätverkskonkurrensen: LCP-resursen måste konkurrera om användarens begränsade nätverksbandbredd. Att skjuta upp icke-kritiska resurser, som analysskript eller CSS för innehåll under fold, frigör bandbredd så att webbläsaren kan fokusera på att ladda ner LCP-resursen snabbare.
- Hosta kritiska resurser på din huvuddomän: Undvik att ladda din LCP-resurs från en annan domän om möjligt. Att upprätta en ny anslutning till en annan server lägger till tidskrävande DNS-uppslagningar och handskakningar.
Plattformsspecifika åtgärder för Load Time
På WordPress:
- Använd en bildoptimeringsplugin: Verktyg som ShortPixel eller Smush kan automatiskt komprimera bilder vid uppladdning, konvertera dem till moderna format som WebP/AVIF och generera responsiva `srcset`-storlekar.
- Ändra storlek på bilder manuellt: Innan du laddar upp, ändra storlek på dina bilder så att de inte är större än de behöver vara. Ladda inte upp en 4000 px bred bild för ett utrymme som bara är 1200 px brett på de största skärmarna.
På ett JS-ramverk:
- Använd en bild-CDN: Detta är en kraftfull lösning. Tjänster som Cloudinary, Imgix eller Akamais Image & Video Manager kan automatisera hela optimeringsprocessen. Du laddar upp en högkvalitativ bild, och de levererar en perfekt anpassad, komprimerad och formaterad version till varje användare via en snabb CDN.
- Utnyttja byggverktyg: När du `importerar` en bild till en komponent i ett modernt ramverk kan byggverktyget (som Webpack eller Vite) automatiskt hasha och optimera filen som en del av byggprocessen.
4. Förkorta Element Render Delay
Resursen har laddats ner färdigt, men den syns inte på skärmen ännu. Detta innebär att webbläsarens huvudtråd är upptagen med andra uppgifter och inte kan rendera elementet. Detta är en annan mycket vanlig och betydande flaskhals.

Universella lösningar för Render Delay
- Skjut upp eller ta bort oanvänd JavaScript: All JS som inte är nödvändig för att rendera den initiala, synliga delen av sidan bör skjutas upp med attributen
deferellerasync. - Använd kritisk CSS: En stor, renderingsblockerande stilmall kan fördröja renderingen. Tekniken med kritisk CSS innebär att extrahera den minsta CSS som behövs för att styla innehållet ovanför fold, infoga den inline i
<head>, och ladda resten av stilarna asynkront [10]. - Bryt upp långa uppgifter: Ett långkörande skript kan blockera huvudtråden under en längre period och förhindra rendering. Detta är också en primär orsak till dåligt Interaction to Next Paint (INP). Bryt upp din kod i mindre, asynkrona delar som ger tillbaka kontrollen till huvudtråden (yielding).
Plattformsspecifika åtgärder för Render Delay
På WordPress:
- Granska dina plugins: För många plugins, särskilt tunga som bildspel eller komplexa sidbyggare, kan lägga till betydande CSS och JS som blockerar huvudtråden. Inaktivera plugins en i taget för att identifiera prestandaslukhål.
- Använd ett lättviktigt tema: Ett uppsvällt tema med dussintals funktioner du inte använder kan vara en stor källa till renderingsblockerande kod. Välj ett prestandafokuserat tema.
- Använd plugin-resurshanterare: Verktyg som Asset CleanUp eller Perfmatters låter dig villkorligt inaktivera CSS och JS från specifika plugins på sidor där de inte behövs.
På ett JS-ramverk:
- Koddelning är nyckeln: Skicka inte all din apps JavaScript i ett enda gigantiskt paket. Dela upp din kod efter rutt (så att användare bara laddar ner koden för sidan de besöker) och efter komponent.
- Lazy-loada komponenter: Använd `React.lazy` och `Suspense` för att lazy-loada komponenter som inte är omedelbart synliga (t.ex. komponenter under fold eller i modaler). Detta håller dem utanför det initiala paketet.
Avancerat: Optimera LCP för efterföljande navigeringar
Att åtgärda det initiala LCP är avgörande, men du kan skapa en dramatiskt snabbare upplevelse för användare när de surfar på din webbplats genom att optimera för efterföljande sidladdningar.
Säkerställ att sidor är kvalificerade för Back/Forward Cache (bfcache)
bfcache är en webbläsaroptimering som lagrar en komplett ögonblicksbild av en sida i minnet när en användare navigerar bort. Om de klickar på bakåtknappen kan sidan återställas omedelbart, vilket resulterar i ett nästan noll LCP. Många sidor är inte kvalificerade för denna cache på grund av saker som `unload`-eventlyssnare. Använd Lighthouse "bfcache"-granskningen för att testa dina sidor och ta bort eventuella blockerande funktioner [11].
Använd Speculation Rules API för förrendering
Speculation Rules API är ett nytt, kraftfullt verktyg som låter dig deklarativt tala om för webbläsaren vilka sidor en användare sannolikt kommer att navigera till härnäst. Webbläsaren kan sedan hämta och förrendera dessa sidor i bakgrunden. När användaren klickar på en länk till en förrenderad sida är navigeringen omedelbar, vilket leder till en fenomenal user experience och ett nästan noll LCP [12]. Du kan definiera dessa regler i en `<script type="speculationrules">`-tagg i din HTML.
<script type="speculationrules">
{
"prerender": [{
"source": "document",
"where": {
"href_matches": "/products/*"
},
"eagerness": "moderate"
}]
}
</script> Detta exempel talar om för webbläsaren att leta efter länkar på den aktuella sidan som går till produktsidor och att börja förrendera dem när en användare hovrar över länken.
Genom att metodiskt arbeta igenom dessa fyra faser och överväga avancerade navigeringsoptimeringar kan du peka ut den exakta orsaken till dina LCP-problem och tillämpa den korrekta, högeffektiva åtgärden.
Referenser
- web.dev: Lab and field data
- Chrome for Developers: Debug Web Vitals in the field
- web.dev: Optimize Largest Contentful Paint
- web.dev: Optimize for a good TTFB
- Cloudflare: What is a CDN?
- web.dev: HTTP/3
- web.dev: Slower is faster? Sending an HTTP 103 response to speed up your site
- web.dev: Optimize LCP with fetchpriority
- web.dev: Use modern image formats
- web.dev: Extract critical CSS
- web.dev: Back/forward cache
- web.dev: Speculation Rules API
CrUX data is 28 days late.
Google provides data 28 days late. CoreDash provides data in real-time. Debug faster.
- Real-Time Insights
- Faster Debugging
- Instant Feedback

