16 méthodes pour différer ou planifier JavaScript
Apprenez à différer et planifier JavaScript

Pourquoi différer ou planifier JavaScript ?
JavaScript peut (et va) ralentir votre site web de plusieurs façons. Cela peut avoir toutes sortes d'impacts négatifs sur les Core Web Vitals. JavaScript peut entrer en compétition pour les ressources réseau, il peut entrer en compétition pour les ressources CPU (bloquer le thread principal) et il peut même bloquer l'analyse d'une page web. Différer et planifier vos scripts peut grandement améliorer les Core Web Vitals.
Dernière révision par Arjen Karel en février 2026
Table of Contents!
- Pourquoi différer ou planifier JavaScript ?
- Comment le timing de JavaScript peut-il affecter les Core Web Vitals ?
- Comment choisir la bonne méthode pour différer ?
- Méthode 1 : Utiliser l'attribut defer
- Méthode 2 : Utiliser l'attribut async
- Méthode 3 : Utiliser les modules
- Méthode 4 : Placer les scripts vers le bas de la page
- Méthode 5 : Injecter des scripts
- Méthode 6 : Injecter des scripts plus tard
- Méthode 7 : Modifier le type de script (et ensuite le rétablir)
- Méthode 9 : Utiliser readystatechange
- Méthode 10 : Utiliser setTimeout sans délai d'attente (timeout)
- Méthode 11 : Utiliser setTimeout avec un délai d'attente (timeout)
- Méthode 12 : Utiliser une promesse pour définir une micro-tâche (microtask)
- Méthode 13 : Utiliser une micro-tâche
- Méthode 14 : Utiliser requestIdleCallback
- Méthode 15 : Utiliser postTask
- Méthode 16 : Utiliser scheduler.yield()
Pour minimiser les effets néfastes que JavaScript peut avoir sur les Core Web Vitals, il est généralement judicieux de spécifier quand un script est mis en file d'attente pour le téléchargement et de planifier quand il peut consommer du temps CPU et bloquer le thread principal.
Comment le timing de JavaScript peut-il affecter les Core Web Vitals ?
Comment le timing de JavaScript peut-il affecter les Core Web Vitals ? Jetez un œil à cet exemple concret. La première page est chargée avec un JavaScript qui bloque le rendu ('render blocking'). Les métriques de rendu ainsi que le Total Blocking Time sont plutôt mauvais. Le deuxième exemple correspond à la même page mais avec le JavaScript différé. Vous verrez que l'image LCP a tout de même pris un gros coup. Le troisième exemple montre le même script exécuté après l'événement 'load' de la page et dont les appels de fonction sont divisés en plus petits morceaux. Ce dernier passe les Core Web Vitals avec une marge confortable.
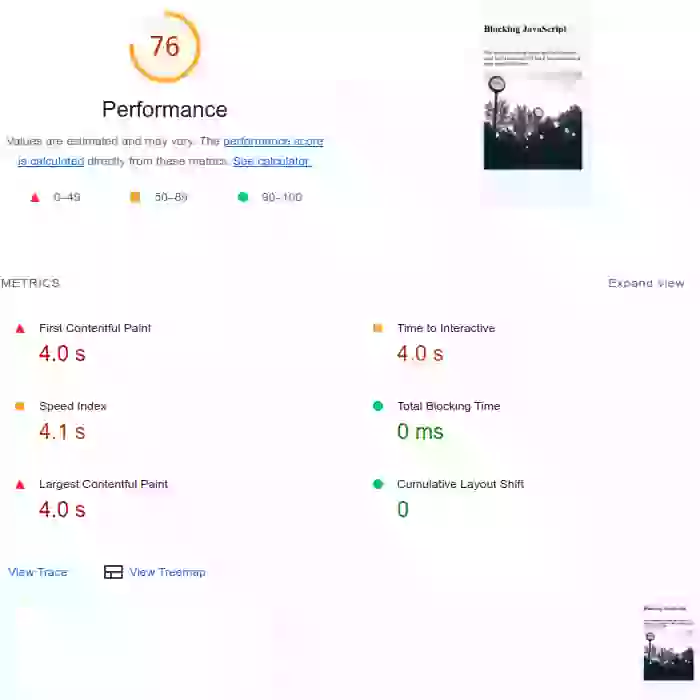

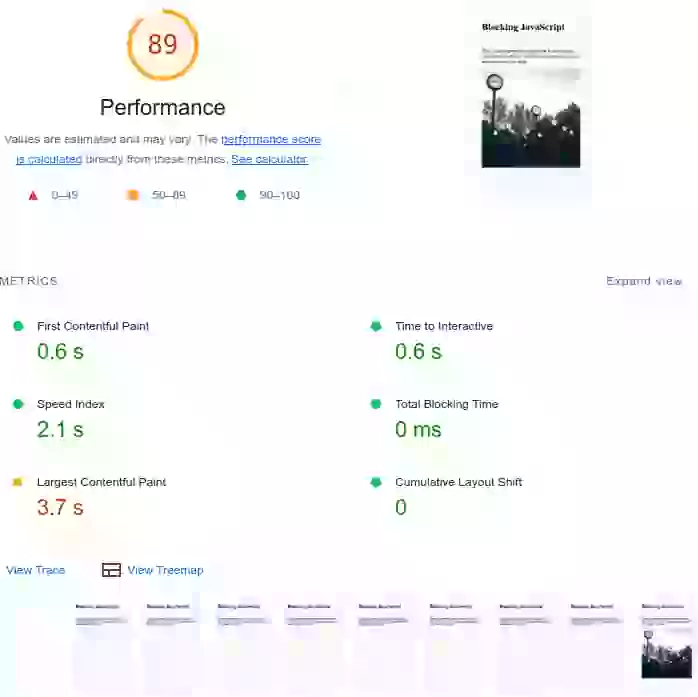
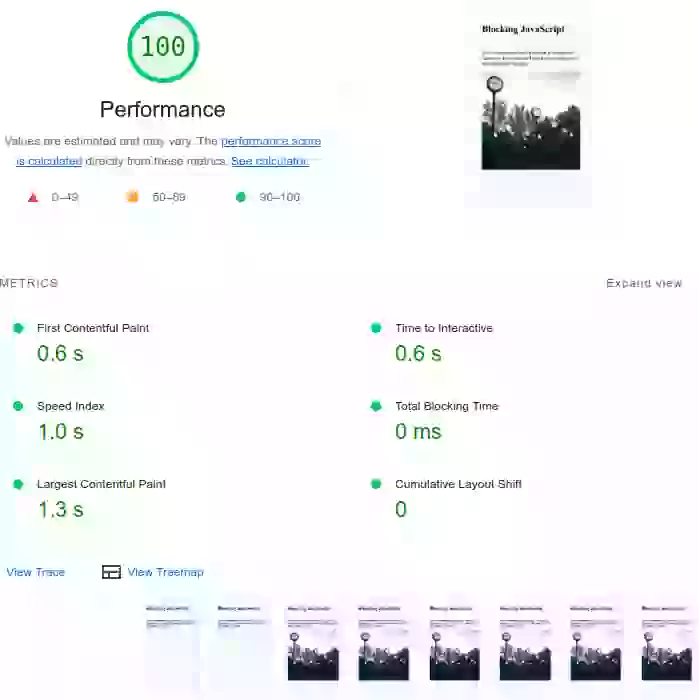
Par défaut, le JavaScript externe dans l'en-tête de la page bloquera la création de l'arbre de rendu. Plus spécifiquement : lorsque le navigateur rencontre un script dans le document, il doit mettre en pause la construction du DOM, passer le contrôle à l'environnement d'exécution JavaScript, et laisser le script s'exécuter avant de poursuivre la construction du DOM. Cela affectera vos métriques de rendu (Largest Contentful Paint et First Contentful Paint).
Le JavaScript différé ou async peut toujours impacter les métriques de rendu, en particulier le Largest Contentful Paint car il s'exécutera, et bloquera le thread principal, une fois que le DOM aura été créé (et les éléments LCP courants comme les images pourraient ne pas avoir été téléchargés).
Les fichiers JavaScript externes vont également entrer en compétition pour les ressources réseau. Les fichiers JavaScript externes sont généralement téléchargés plus tôt que les images. Si vous téléchargez trop de scripts, le téléchargement de vos images sera retardé.
Enfin et surtout, JavaScript pourrait bloquer ou retarder l'interaction utilisateur. Lorsqu'un script utilise des ressources CPU (bloquant le thread principal) un navigateur ne répondra pas aux entrées (clics, défilement, etc.) tant que ce script ne sera pas terminé. Cela affecte directement votre score Interaction to Next Paint (INP).
L'impact est mesurable. Selon le Web Almanac 2025, seulement 15 % des pages mobiles réussissent l'audit des ressources bloquant le rendu. Le Total Blocking Time médian sur mobile est de 1 916 millisecondes. C'est presque 2 secondes entières pendant lesquelles le navigateur ne peut pas répondre aux entrées de l'utilisateur. Choisir la bonne méthode pour différer chaque script est le moyen de faire baisser ce chiffre.
Comment le fait de planifier ou de différer JavaScript corrige-t-il les Core Web Vitals ?
Planifier ou différer JavaScript ne corrige pas les Core Web Vitals en soi. Il s'agit plutôt d'utiliser le bon outil pour la bonne situation. En règle générale, vous devriez essayer de retarder vos scripts le moins possible, mais de les mettre en file d'attente pour le téléchargement et de les exécuter au moment approprié.
Comment choisir la bonne méthode pour différer ?
Tous les scripts ne sont pas identiques et chaque script a sa propre fonctionnalité. Certains scripts sont importants à avoir tôt dans le processus de rendu, d'autres non.
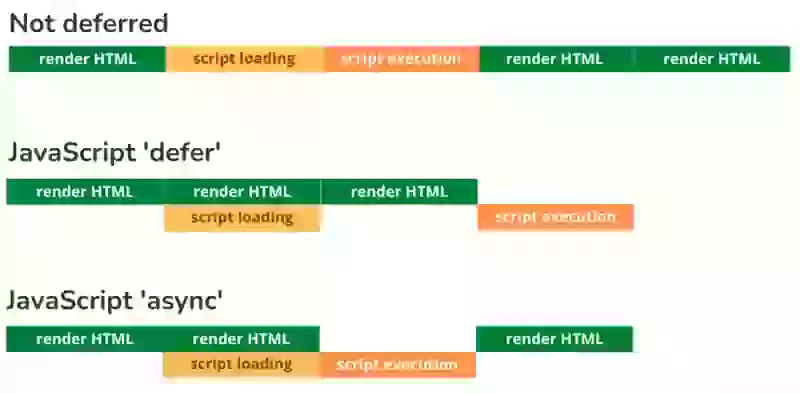
J'aime catégoriser les JavaScripts en 4 groupes en fonction de leur niveau d'importance.
1. Critiques pour le rendu. Ce sont les scripts qui vont modifier l'apparence d'une page web. S'ils ne se chargent pas, la page ne paraîtra pas complète. Ces scripts doivent être évités à tout prix. Si vous ne pouvez pas les éviter pour une raison quelconque, ils ne doivent pas être différés. Par exemple un slider supérieur ou un script de test A/B.
2. Critiques. Ces scripts ne changeront pas l'apparence d'une page web (pas trop) mais la page ne fonctionnera pas bien sans eux. Ces scripts devraient être différés (defer) ou asynchrones (async). Par exemple les scripts de votre menu.
3. Importants. Ce sont des scripts que vous voulez charger car ils sont précieux pour vous ou pour le visiteur. J'ai tendance à charger ces scripts après que l'événement load a été déclenché. Par exemple l'analytique ou un bouton 'retour en haut'.
4. Agréables à avoir. Ce sont des scripts dont vous pouvez vous passer si vous en avez absolument besoin. Je charge ces scripts avec la priorité la plus basse et ne les exécute que lorsque le navigateur est inactif. Par exemple un widget de chat ou un bouton facebook.
Méthode 1 : Utiliser l'attribut defer
Les scripts avec l'attribut defer se téléchargeront en parallèle et seront ajoutés à la file d'attente JavaScript defer. Juste avant que le navigateur ne déclenche l'événement DOMContentLoaded, tous les scripts de cette file d'attente s'exécuteront dans l'ordre dans lequel ils apparaissent dans le document.
<script src='javascript.js'></script> L'« astuce defer » corrige généralement de nombreux problèmes, en particulier les métriques de rendu. Malheureusement il n'y a aucune garantie, cela dépend de la qualité des scripts. Les scripts différés s'exécuteront une fois que tous les scripts auront été chargés et que le HTML aura été analysé (DOMContentLoaded). L'élément LCP (généralement une grande image) pourrait ne pas être chargé d'ici là et les scripts différés causeront tout de même un retard dans le LCP.
Quand l'utiliser :
Utilisez des scripts différés pour les scripts Critiques qui sont nécessaires le plus tôt possible.
Avantages :
- Les scripts différés se téléchargeront en parallèle
- Le DOM sera disponible au moment de l'exécution
Inconvénients :
- Les scripts différés pourraient retarder vos métriques LCP
- Les scripts différés bloqueront le thread principal une fois qu'ils seront exécutés
- Il pourrait ne pas être sûr de différer des scripts lorsque des scripts en ligne ou async dépendent d'eux
Méthode 2 : Utiliser l'attribut async
Les scripts avec l'attribut async se téléchargent en parallèle et s'exécuteront immédiatement après avoir terminé leur téléchargement.
<script src='javascript.js'></script> Les scripts async feront peu pour corriger vos problèmes de vitesse de page. C'est super qu'ils soient téléchargés en parallèle, mais c'est à peu près tout. Une fois qu'ils sont téléchargés, ils bloqueront le thread principal lors de leur exécution.
Quand l'utiliser :
Utilisez les scripts async pour les scripts Critiques qui sont nécessaires le plus tôt possible et qui sont autonomes (ne dépendent pas d'autres scripts).
Avantages :
- Les scripts async se téléchargeront en parallèle.
- Les scripts async s'exécuteront le plus tôt possible.
Inconvénients :
- DOMContentLoaded peut se produire aussi bien avant qu'après async.
- L'ordre d'exécution des scripts sera inconnu à l'avance.
- Vous ne pouvez pas utiliser des scripts async qui dépendent d'autres scripts async ou différés
Pour une comparaison détaillée de ces deux approches, voir defer vs async et comment cela affecte les Core Web Vitals.
Méthode 3 : Utiliser les modules
Les scripts modulaires sont différés par défaut à moins qu'ils n'aient l'attribut async. Dans ce cas, ils seront traités comme des scripts async
<script src='javascript.js'></script> Les modules sont une nouvelle façon de penser à JavaScript et corrigent certains défauts de conception. À part cela, l'utilisation de modules de script n'accélérera pas votre site web.
Quand l'utiliser :
Lorsque votre application est construite de manière modulaire, il est logique d'utiliser également des modules JavaScript.
Avantages :
- Les modules sont différés par défaut
- Les modules sont plus faciles à maintenir et fonctionnent très bien avec la conception web modulaire
- Les modules permettent un découpage du code facile avec des imports dynamiques où vous n'importez que les modules dont vous avez besoin à un certain moment.
Inconvénients :
- Les modules en eux-mêmes n'amélioreront pas les Core Web Vitals
- L'importation de modules juste-à-temps ou à la volée pourrait être lente et aggraver l'INP
Méthode 4 : Placer les scripts vers le bas de la page
Les scripts en pied de page sont mis en file d'attente pour être téléchargés plus tard. Cela donnera la priorité aux autres ressources qui se trouvent dans le document au-dessus de la balise script.
<html>
<head></head>
<body>
[your page contents here]
<script defer src='javascript.js'></script>
</body>
</html> Placer vos scripts en bas de la page est une technique intéressante. Cela planifiera d'autres ressources (comme les images) avant vos scripts. Cela augmentera les chances qu'elles soient disponibles pour le navigateur et peintes à l'écran avant que les fichiers JavaScript n'aient terminé leur téléchargement et que le thread principal ne soit bloqué par l'exécution du script. Pourtant... aucune garantie.
Quand l'utiliser :
Lorsque vos scripts sont déjà assez performants mais que vous souhaitez prioriser légèrement d'autres ressources comme les images et les polices web.
Avantages :
- Placer les scripts en bas de la page ne nécessite pas beaucoup de connaissances.
- Si c'est bien fait, il n'y a aucun risque que cela casse votre page
Inconvénients :
- Les scripts critiques pourraient être téléchargés et exécutés plus tard
- Cela ne corrige aucun problème JavaScript sous-jacent
Méthode 5 : Injecter des scripts
Les scripts injectés sont traités comme des scripts async. Ils sont téléchargés en parallèle et sont exécutés immédiatement après le téléchargement.
<script>
const loadScript = (scriptSource) => {
const script = document.createElement('script');
script.src = scriptSource;
document.head.appendChild(script);
}
// call the loadscript function that injects 'javascript.js'
loadScript('javascript.js');
</script> Du point de vue des Core Web Vitals, cette technique est exactement la même que l'utilisation de <script async>.
Quand l'utiliser :
Cette méthode est souvent utilisée par les scripts tiers qui se déclenchent le plus tôt possible. L'appel de fonction permet d'encapsuler et de compresser facilement le code.
Avantages :
- Code contenu, qui injecte un script async.
Inconvénients :
- DOMContentLoaded peut se produire à la fois avant et après le chargement du script.
- L'ordre d'exécution des scripts sera inconnu à l'avance.
- Vous ne pouvez pas l'utiliser sur des scripts qui dépendent d'autres scripts async ou différés
Méthode 6 : Injecter des scripts plus tard
Les scripts agréables à avoir ne devraient à mon avis jamais être chargés de manière différée. Ils devraient être injectés au moment le plus opportun. Dans l'exemple ci-dessous, le script s'exécutera après que le navigateur aura envoyé l'événement 'load'.
<script>
window.addEventListener('load', function () {
// see method 5 for the loadscript function
loadScript('javascript.js');
});
</script> C'est la première technique qui améliorera de manière fiable le Largest Contentful Paint. Toutes les ressources importantes, y compris les images, seront téléchargées lorsque le navigateur déclenchera l'événement 'load'. Cela pourrait introduire toutes sortes de problèmes car il se peut que l'événement load mette beaucoup de temps à être appelé.
Quand l'utiliser :
Pour les scripts agréables à avoir qui n'ont aucune raison d'impacter les métriques de rendu.
Avantages :
- N'entrera pas en compétition pour les ressources critiques car cela injectera le script une fois que la page et ses ressources seront chargées
Inconvénients :
- Si votre page est mal conçue en termes de Core Web Vitals, il pourrait falloir beaucoup de temps pour que la page envoie l'événement 'load'
- Vous devez faire attention à ne pas appliquer cela aux scripts critiques (comme le lazy loading, le menu, etc.)
Méthode 7 : Modifier le type de script (et ensuite le rétablir)
Si une balise script est trouvée quelque part sur la page qui 1. possède un attribut type et 2. l'attribut type n'est pas "text/javascript", le script ne sera pas téléchargé ni exécuté par un navigateur. De nombreux chargeurs JavaScript (comme RocketLoader de CloudFlare) reposent sur ce principe. L'idée est assez simple et élégante.
D'abord, tous les scripts sont réécrits ainsi :
<script src="javascript.js"></script> Ensuite, à un moment donné pendant le processus de chargement, ces scripts sont reconvertis en 'javascripts normaux'.
Quand l'utiliser :
Ce n'est pas une méthode que je recommanderais. Corriger l'impact de JavaScript nécessitera bien plus que de simplement déplacer chaque script un peu plus loin dans la file d'attente. D'un autre côté, si vous avez peu de contrôle sur les scripts exécutés sur la page ou si vous avez des connaissances insuffisantes en JavaScript, cela pourrait être votre meilleure option.
Avantages :
- C'est facile, il suffit d'activer rocket loader ou un autre plugin et tous vos scripts s'exécutent maintenant à un moment un peu plus tard.
- Cela corrigera probablement vos métriques de rendu à condition que vous n'ayez pas utilisé de lazy loading basé sur JS.
- Cela fonctionnera pour les scripts en ligne et externes.
Inconvénients :
- Vous n'aurez aucun contrôle précis sur le moment où les scripts s'exécutent
- Un script mal écrit pourrait casser
- Cela utilise du JavaScript pour corriger du JavaScript
- Cela ne fait rien pour corriger les scripts à exécution longue
Méthode 8 : Utiliser l'intersection observer
Avec l'intersection observer, vous pouvez exécuter une fonction (qui dans ce cas charge un JavaScript externe) lorsqu'un élément défile dans la fenêtre d'affichage visible (viewport).
<script>
const handleIntersection = (entries, observer) => {
if (entries?.[0].isIntersecting) {
// load your script or execute another
function like trigger a lazy loaded element
loadScript('javascript.js');
// remove the observer
observer.unobserve(entries?.[0].target);
}
};
const Observer = new window.IntersectionObserver()
Observer.observe(document.querySelector('footer'));
</script> C'est de loin la méthode la plus efficace qui soit pour différer JavaScript. Ne chargez que les scripts dont vous avez besoin, juste avant d'en avoir besoin. Malheureusement, la vraie vie est rarement aussi propre et peu de scripts peuvent être liés à un élément qui défile pour apparaître à l'écran.
Quand l'utiliser :
Utilisez cette technique autant que possible ! Chaque fois qu'un script n'interagit qu'avec un composant hors écran (comme une carte, un slider, un formulaire), c'est la meilleure façon d'injecter ce script.
Avantages :
- N'interférera pas avec le LCP et le FCP des Core Web Vitals
- N'injectera jamais de scripts qui ne sont pas utilisés. Cela améliorera l'INP
Inconvénients :
- Ne devrait pas être utilisé avec des composants qui pourraient se trouver dans la fenêtre d'affichage visible
- Est plus difficile à maintenir qu'un simple <script src="...">
- Pourrait introduire un décalage de mise en page (layout shift)
Méthode 9 : Utiliser readystatechange
document.readystate peut être utilisé comme alternative aux événements 'DOMContentloaded' et 'load'. L'état 'interactive' (readystatechange) est généralement un bon endroit pour appeler des scripts critiques qui doivent modifier le DOM ou ajouter des gestionnaires d'événements.
L'état 'complete' est un bon endroit pour appeler des scripts qui sont moins critiques.
document.addEventListener('readystatechange', (event) => {
if (event.target.readyState === 'interactive') {
initLoader();
} else if (event.target.readyState === 'complete') {
initApp();
}
}); Méthode 10 : Utiliser setTimeout sans délai d'attente (timeout)
setTimeout est une méthode mal vue et pourtant largement sous-estimée dans la communauté de la vitesse de page (pagespeed). setTimeout a mauvaise réputation car il est souvent mal utilisé. Beaucoup de développeurs pensent que setTimeout ne peut être utilisé que pour retarder l'exécution d'un script du nombre défini de millisecondes. Bien que ce soit vrai, setTimeout fait en réalité quelque chose de bien plus intéressant. Il crée une nouvelle tâche à la fin de la boucle d'événements (event loop) du navigateur. Ce comportement peut être utilisé pour planifier vos tâches efficacement. Il peut également être utilisé pour diviser de longues tâches en tâches plus petites et distinctes
<script>
setTimeout(() => {
// load a script or execute another function
console.log('- I am called from a 0ms timeOut()')
}, 0);
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I am called from a 0ms timeOut()
*/
</script> Quand l'utiliser :
setTimeout crée une nouvelle tâche dans la boucle d'événements du navigateur. Utilisez-le lorsque votre thread principal est bloqué par de nombreux appels de fonctions qui s'exécutent de manière séquentielle.
Avantages :
- Peut diviser du code à exécution longue en plus petits morceaux.
Inconvénients :
- setTimeout est une méthode plutôt rudimentaire et n'offre pas de priorisation pour les scripts importants.
- Ajoutera le code devant être exécuté à la fin de la boucle
Méthode 11 : Utiliser setTimeout avec un délai d'attente (timeout)
Les choses deviennent encore plus intéressantes lorsque nous appelons setTimeout avec un délai d'attente de plus de 0ms
<script>
setTimeout(() => {
// load a script or execute another function
console.log('- I am called from a 10ms timeOut()')
}, 10);
setTimeout(() => {
// load a script or execute another function
console.log('- I am called from a 0ms timeOut()')
}, 0);
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I am called from a 0ms timeOut()
- I am called from a 10ms timeOut()
*/
</script> Quand l'utiliser :
Lorsque vous avez besoin d'une méthode facile pour planifier un script après l'autre, un petit délai d'attente fera l'affaire
Avantages :
- Pris en charge sur tous les navigateurs
Inconvénients :
- N'offre pas de planification avancée
Méthode 12 : Utiliser une promesse pour définir une micro-tâche (microtask)
La création d'une micro-tâche est également une manière intéressante de planifier JavaScript. Les micro-tâches sont planifiées pour s'exécuter immédiatement après que la boucle d'exécution en cours est terminée.
<script>
const myPromise = new Promise((resolve, reject) => {
resolve();
}).then(
() => {
console.log('- I was scheduled after a promise')
}
);
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I was scheduled after a promise
*/
</script> Quand l'utiliser :
Lorsqu'une tâche doit être planifiée immédiatement après une autre tâche.
Avantages :
- La micro-tâche sera planifiée immédiatement après que la tâche a terminé son exécution.
- Une micro-tâche peut être utilisée pour retarder des morceaux de code JavaScript moins importants dans le même événement.
Inconvénients :
- Ne divisera pas le thread principal en de plus petites parties. Le navigateur n'aura aucune chance de répondre aux entrées de l'utilisateur.
- Vous n'aurez probablement jamais besoin d'utiliser les micro-tâches pour améliorer les Core Web Vitals à moins de savoir déjà exactement ce que vous faites.
Méthode 13 : Utiliser une micro-tâche
Le même résultat peut être obtenu en utilisant queueMicrotask(). L'avantage d'utiliser queueMicrotask() par rapport à une promesse est que c'est légèrement plus rapide et que vous n'avez pas besoin de gérer vos promesses.
<script>
queueMicrotask(() => {
console.log('- I am a microtask')
})
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I am a microtask
*/
</script> Méthode 14 : Utiliser requestIdleCallback
La méthode window.requestIdleCallback() met en file d'attente une fonction pour être appelée pendant les périodes d'inactivité du navigateur. Cela permet aux développeurs d'effectuer des tâches en arrière-plan et de faible priorité sur la boucle d'événements principale, sans impacter les événements critiques en termes de latence tels que l'animation et la réponse aux entrées. Les fonctions sont généralement appelées dans l'ordre du premier entré, premier sorti ; cependant, les rappels (callbacks) pour lesquels un délai d'attente (timeout) est spécifié peuvent être appelés dans le désordre si nécessaire afin de les exécuter avant que le délai ne s'écoule.
<script>
requestIdleCallback(() => {
const script = document.createElement('script');
script.src = 'javascript.js';
document.head.appendChild(script);
});
</script> Quand l'utiliser :
Utilisez ceci pour les scripts qui sont Agréables à avoir ou pour gérer des tâches non critiques après une entrée de l'utilisateur
Avantages :
- Exécute JavaScript avec un impact minimal pour l'utilisateur
- Améliorera très probablement l'INP
Inconvénients :
- Aucune garantie que le code se déclenchera un jour
Méthode 15 : Utiliser postTask
La méthode scheduler.postTask() permet aux utilisateurs de spécifier optionnellement un délai minimum avant que la tâche ne s'exécute, une priorité pour la tâche, et un signal qui peut être utilisé pour modifier la priorité de la tâche et/ou l'annuler (abort). Elle retourne une promesse qui est résolue avec le résultat de la fonction de rappel (callback) de la tâche, ou rejetée avec la raison de l'annulation ou une erreur lancée dans la tâche.
<script>
scheduler.postTask(() => {
const script = document.createElement('script');
script.src = 'javascript.js';
document.head.appendChild(script);
}, { priority: 'background' });
</script> Quand l'utiliser :
postTask est la bonne API pour planifier des scripts lorsque vous avez besoin d'un contrôle précis sur la priorité.
Avantages :
- Contrôle complet sur la planification de l'exécution de JavaScript !
Inconvénients :
- Non pris en charge dans Safari. Pris en charge dans Chrome 94+, Edge 94+, et Firefox 142+. Utilisez la détection de fonctionnalités et un fallback setTimeout pour une couverture complète.
Méthode 16 : Utiliser scheduler.yield()
scheduler.yield() est la manière la plus récente de diviser les tâches longues. Elle retourne une promesse qui se résout dans une nouvelle tâche, donnant au navigateur une chance de répondre aux entrées de l'utilisateur entre les morceaux de travail. Contrairement à setTimeout, la continuation obtient la priorité sur les autres tâches en file d'attente, de sorte que votre code reprend là où il s'est arrêté sans être repoussé à la fin de la file.
<script>
async function processItems(items) {
for (const item of items) {
doWork(item);
await scheduler.yield();
}
}
</script> C'est de loin le meilleur outil pour améliorer l'INP. Les tâches longues qui bloquent le thread principal pendant des centaines de millisecondes peuvent être divisées en plus petits morceaux, chacun séparé par un point de yield (yielding). Le navigateur peut gérer les entrées de l'utilisateur à chaque point de yield. Pour une explication pratique de ce modèle, voir comment faire un yield au thread principal.
Safari ne prend pas encore en charge scheduler.yield(), incluez donc toujours un fallback :
<script>
function yieldToMain() {
if (globalThis.scheduler?.yield) {
return scheduler.yield();
}
return new Promise(resolve => {
setTimeout(resolve, 0);
});
}
async function processItems(items) {
for (const item of items) {
doWork(item);
await yieldToMain();
}
}
</script> Quand l'utiliser :
Utilisez ceci chaque fois que vous avez du JavaScript à exécution longue qui bloque le thread principal. C'est l'approche recommandée pour améliorer l'INP sur les gestionnaires d'interaction et tout code qui traite des données dans une boucle.
Avantages :
- Divise les tâches longues sans perdre votre place dans la file d'attente
- La continuation s'exécute avant les autres tâches en file d'attente (contrairement à setTimeout qui va à la fin de la file)
- Améliore directement l'INP en donnant au navigateur une chance de répondre aux entrées de l'utilisateur
Inconvénients :
- Non pris en charge dans Safari. Pris en charge dans Chrome 129+, Edge 129+, et Firefox 142+.
- Nécessite un fallback pour une couverture complète des navigateurs (setTimeout fonctionne comme un polyfill)
Après avoir appliqué ces techniques, vérifiez l'amélioration avec le Real User Monitoring. Les scores Lighthouse sont un point de départ, mais les données de terrain (field data) provenant d'utilisateurs réels sont ce que Google utilise pour le classement. CoreDash suit l'INP et tous les Core Web Vitals des visiteurs réels, de sorte que vous pouvez voir si votre stratégie de différé fonctionne réellement en production.
Je fais passer les sites aux Core Web Vitals.
500K+ pages chez les grands éditeurs européens et les plateformes e-commerce. J'écris les fix moi-même et je les vérifie avec vos données terrain.
Ma méthode
