Solucionar e identificar problemas de Time to First Byte (TTFB)
Aprenda a depurar problemas de Time to First Byte en sus páginas usando datos RUM, encabezados Server-Timing y análisis sistemático de sub-partes del TTFB

Encontrar y solucionar problemas de Time to First Byte (TTFB)
Este artículo forma parte de nuestra guía de Time to First Byte (TTFB). TTFB es una métrica de diagnóstico que mide el tiempo entre la solicitud de una página por parte del usuario y la recepción del primer byte de la respuesta por parte del navegador. Aunque TTFB no es en sí mismo un Core Web Vital, influye directamente tanto en First Contentful Paint (FCP) como en Largest Contentful Paint (LCP). Un buen TTFB es inferior a 800 milisegundos en el percentil 75.
En nuestro artículo anterior hablamos sobre el Time to First Byte. Si desea repasar los conceptos básicos, ese es un excelente punto de partida.
En este artículo nos centraremos en identificar los diferentes problemas de Time to First Byte y luego explicaremos cómo solucionarlos.
CONSEJO TTFB: la mayoría de las veces el TTFB será mucho peor para los visitantes nuevos, ya que no tienen una caché DNS para su sitio. Al rastrear el TTFB tiene mucho sentido distinguir entre visitantes nuevos y recurrentes.
Table of Contents!
- Encontrar y solucionar problemas de Time to First Byte (TTFB)
- Paso 1: Verificar el TTFB en Search Console
- Paso 1b: Usar el encabezado Server-Timing para un análisis más profundo
- Paso 2: Configurar el seguimiento RUM
- Paso 2b: Establecer una línea base de rendimiento
- Paso 3: Identificar problemas de Time to First Byte
- Paso 4: Profundizar en los problemas y solucionarlos
- Paso 5: Lista de soluciones rápidas para problemas comunes de TTFB
- Medir el TTFB con JavaScript
- Lectura adicional: guías de optimización
- Sub-partes del TTFB: guías completas
Paso 1: Verificar el TTFB en Search Console
"El primer paso para la recuperación es admitir que tienes un problema." Así que antes de hacer nada para solucionar el Time to First Byte, asegurémonos de que realmente tenemos un problema con el TTFB.
Desafortunadamente, el Time to First Byte no se reporta en Google Search Console, por lo que debemos recurrir a pagespeed.web.dev para consultar los datos CrUX de nuestro sitio. Afortunadamente los pasos son fáciles: navegue a pagespeed.web.dev, ingrese la URL de su página y asegúrese de que el botón "origin" esté marcado (ya que necesitamos datos de todo el sitio y no solo de la página de inicio). Ahora alterne entre Mobile y Desktop y verifique el Time to First Byte para ambos tipos de dispositivo.
En el ejemplo a continuación verá un sitio que no pasa los Core Web Vitals debido a un TTFB alto.
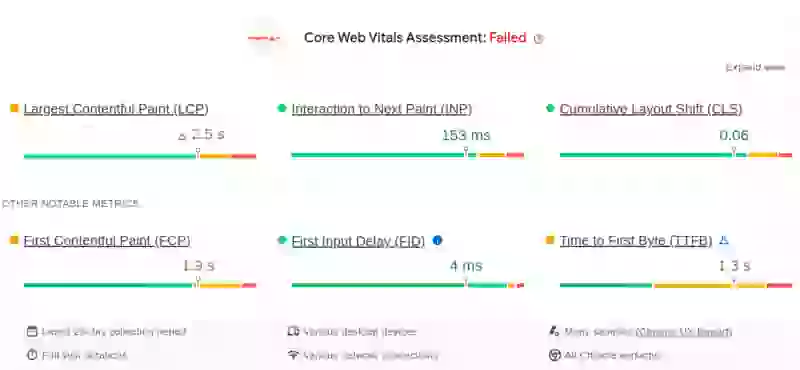
Paso 1b: Usar el encabezado Server-Timing para un análisis más profundo
El encabezado de respuesta HTTP Server-Timing permite que su servidor comunique métricas de rendimiento del backend directamente al navegador. Esto hace posible identificar exactamente qué parte del procesamiento del servidor es lenta sin necesidad de acceder a los registros del servidor.
Un encabezado Server-Timing típico se ve así:
Server-Timing: db;dur=53, app;dur=120, cache;desc="miss"
En este ejemplo el servidor reporta tres valores de tiempo:
- db;dur=53: la consulta a la base de datos tomó 53 milisegundos.
- app;dur=120: la lógica de la aplicación (renderizado de plantillas, llamadas API, etc.) tomó 120 milisegundos.
- cache;desc="miss": la caché del servidor no se utilizó para esta solicitud (un fallo de caché).
Puede leer estos valores en Chrome DevTools abriendo la pestaña Network, seleccionando la solicitud del documento y desplazándose hasta la sección "Server Timing" en la pestaña Timing. Los valores también son accesibles a través de la API PerformanceServerTiming en JavaScript:
const [navigation] = performance.getEntriesByType('navigation');
if (navigation.serverTiming) {
navigation.serverTiming.forEach(entry => {
console.log(`${entry.name}: ${entry.duration}ms (${entry.description})`);
});
} Si su servidor aún no envía encabezados Server-Timing, considere agregarlos. La mayoría de los frameworks web lo hacen sencillo. En PHP puede agregar el encabezado antes de cualquier salida:
header('Server-Timing: db;dur=' . $dbTime . ', app;dur=' . $appTime); En Node.js con Express:
res.setHeader('Server-Timing', `db;dur=${dbTime}, app;dur=${appTime}`); El encabezado Server-Timing es especialmente útil cuando se combina con Real User Monitoring porque le permite correlacionar el rendimiento del lado del servidor con el TTFB que experimentan los usuarios reales. Aprenda más sobre cómo 103 Early Hints puede reducir aún más el TTFB percibido enviando hints de recursos antes de que la respuesta completa esté lista.
Paso 2: Configurar el seguimiento RUM
El Time to First Byte es una métrica complicada. No podemos simplemente confiar en pruebas sintéticas para medir el TTFB porque en la vida real otros factores contribuirán a las fluctuaciones en el TTFB. Para obtener respuestas a todas las preguntas anteriores necesitamos medir los datos en la vida real y registrar cualquier problema que pueda ocurrir con el Time to First Byte. Esto se llama Real User Monitoring, y hay varias formas de habilitar el seguimiento RUM. Hemos desarrollado CoreDash específicamente para estos casos de uso. CoreDash es una herramienta RUM de bajo costo, rápida y efectiva que hace el trabajo. Por supuesto, hay muchas soluciones RUM disponibles y también harán el trabajo (aunque a un precio más alto).
Cómo pensar sobre el TTFB: Imagine que un servidor web es la cocina de un restaurante, y un usuario que solicita una página web es un cliente hambriento que hace un pedido. El Time to First Byte (TTFB) es el intervalo de tiempo entre que el cliente hace su pedido y la cocina comienza a preparar la comida.
Así que el TTFB NO se trata de qué tan rápido se cocina toda la comida (First Contentful Paint) y se sirve (Largest Contentful Paint), sino más bien de qué tan receptiva es la cocina ante la solicitud inicial.
El seguimiento RUM se compara con encuestar a los clientes para comprender su experiencia gastronómica. Podría descubrir que los clientes sentados más lejos de la cocina reciben menos atención del camarero y son atendidos más tarde, o que los clientes recurrentes reciben un trato preferencial mientras que los nuevos visitantes tienen que esperar más por una mesa.
Paso 2b: Establecer una línea base de rendimiento
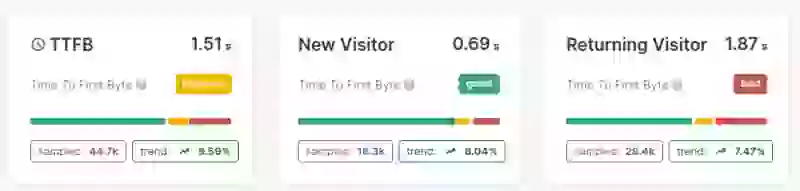
Antes de realizar cualquier cambio, establezca una línea base para su TTFB. Registre el percentil 75 del TTFB en las siguientes dimensiones, ya que esto le ayudará a medir la efectividad de sus optimizaciones más adelante:
- TTFB general (móvil y escritorio por separado): capture el percentil 75 para cada tipo de dispositivo.
- Las 10 páginas principales por tráfico: registre el TTFB para sus páginas de mayor tráfico individualmente.
- Visitantes nuevos vs. visitantes recurrentes: los visitantes nuevos típicamente tienen un TTFB más alto debido a la sobrecarga de DNS y conexión.
- Los 5 países principales por tráfico: la distancia geográfica a su servidor afecta significativamente el TTFB.
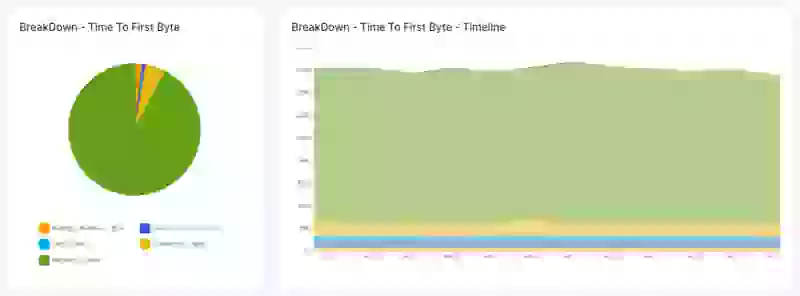
- Desglose de sub-partes del TTFB: registre el percentil 75 para cada sub-parte (espera, caché, DNS, conexión, solicitud).
Documente estos números en una hoja de cálculo. Después de implementar cada optimización, espere al menos 7 días para recopilar suficientes datos RUM antes de comparar resultados. Un buen enfoque es abordar una sub-parte del TTFB a la vez, medir y luego pasar a la siguiente.
Paso 3: Identificar problemas de Time to First Byte
Aunque el Chrome User Experience Report (CrUX) de Google proporciona datos de campo valiosos, no ofrece detalles específicos sobre las causas de un TTFB alto. Para mejorar el TTFB de manera efectiva necesitamos saber exactamente qué está sucediendo a un nivel más detallado. En este punto tiene sentido distinguir entre un TTFB que falla en general y un TTFB que falla bajo condiciones específicas (aunque en la realidad siempre habrá una mezcla).
3.1 El TTFB falla en general
- Verificar tiempos de "solicitud" generalmente pobres: Tiempos de solicitud pobres significan que el "problema" está en el tiempo que le toma al servidor generar la página. Esta es la causa más común de puntuaciones TTFB deficientes.
- Verificar otras sub-partes del TTFB pobres: El TTFB no es solo una métrica única sino que puede desglosarse en múltiples partes, cada una con su propio potencial de optimización. Si la duración de espera, la duración de caché, la duración de búsqueda DNS o la duración de conexión son lentas, probablemente necesitará ajustar la configuración de su servidor o comenzar a buscar un alojamiento de mejor calidad.
3.2 El TTFB falla bajo condiciones específicas
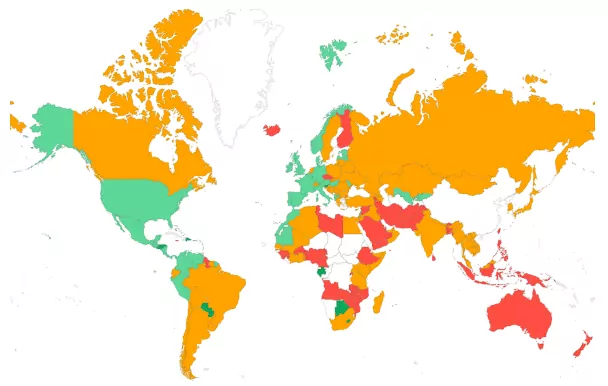
- Segmentación por país: Comprender la distribución geográfica de un TTFB alto es importante, especialmente para sitios web con audiencia global. Si está sirviendo sus páginas desde un servidor en un solo país (sin caché de borde CDN), la distancia física entre la ubicación del usuario y el servidor que aloja el sitio web causará todo tipo de retrasos e impactará el TTFB. Considere configurar Cloudflare u otro CDN para acercar su contenido a los usuarios de todo el mundo.
- Segmentación por caché: El almacenamiento en caché puede reducir el TTFB al omitir la generación del HTML en el lado del servidor. Desafortunadamente es común que el caché esté deshabilitado o se omita por muchas razones. Por ejemplo, el caché puede estar deshabilitado para usuarios conectados, páginas del carrito de compras, páginas con cadenas de consulta (por ejemplo, de Google Ads), páginas de resultados de búsqueda y páginas de pago. Si su sitio web usa caché (de borde), use el seguimiento RUM para verificar la tasa de aciertos de caché.
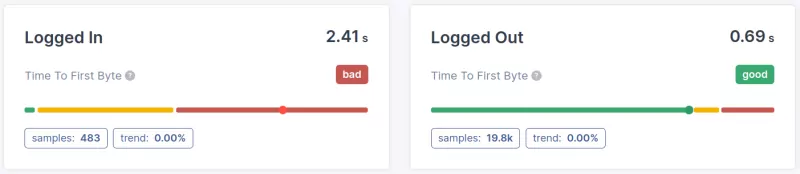
- Segmentación por página (cluster): La diferencia en el rendimiento del Time to First Byte (o la falta de diferencia) entre páginas o tipos de página es otra cosa que necesitamos determinar. Saber qué páginas no pasan la métrica TTFB proporcionará información valiosa sobre cómo mejorar el Time to First Byte.

- Segmentación por redirecciones: El tiempo de redirección se suma directamente al TTFB. Cada redirección agrega tiempo adicional antes de que el servidor web pueda comenzar a cargar la página. Medir y eliminar redirecciones innecesarias puede ayudar a mejorar el TTFB. Para un análisis más profundo de la optimización de redirecciones, consulte nuestra guía sobre la sub-parte de duración de espera del TTFB.

- Otra segmentación: Aunque segmentar por las variables anteriores cubre los sospechosos habituales, cada sitio es único y tiene sus propios desafíos. Afortunadamente el seguimiento RUM está diseñado para permitir la segmentación por muchas más variables como RAM del dispositivo, velocidad de red, tipo de dispositivo, sistema operativo, variables personalizadas y mucho más.
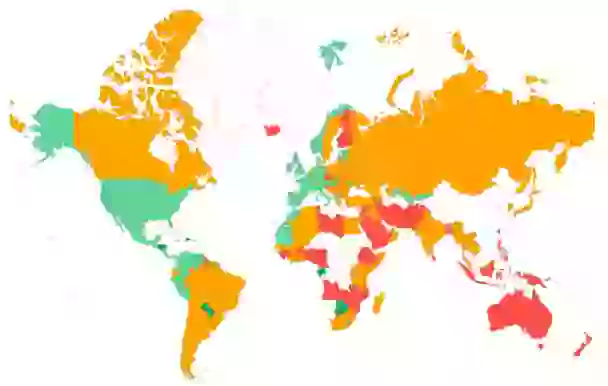
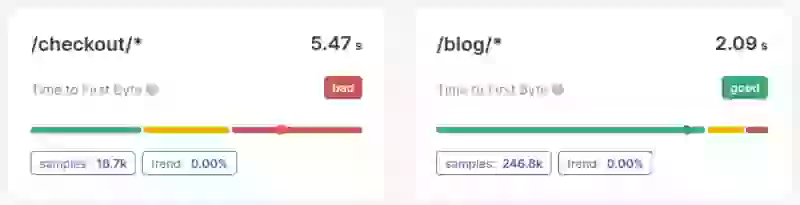

Paso 4: Profundizar en los problemas y solucionarlos
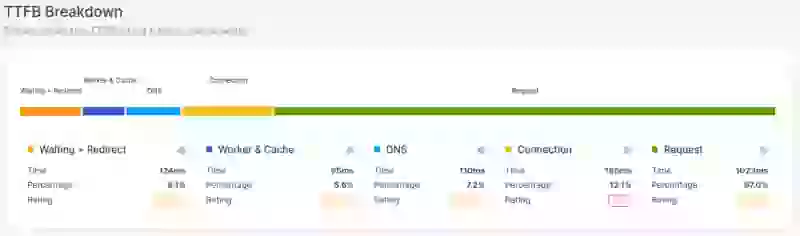
Las sub-partes del Time to First Byte (TTFB) son:
- Espera + Redirección (o duración de espera)
- Worker + Caché (o duración de caché)
- DNS (o duración de DNS)
- Conexión (o duración de conexión)
- Solicitud (o duración de solicitud)
Paso 5: Lista de soluciones rápidas para problemas comunes de TTFB
Según la sub-parte que más contribuye a su TTFB, aquí hay una referencia rápida de las soluciones más comunes:
| Sub-parte del TTFB | Causa más común | Solución rápida |
|---|---|---|
| Duración de espera | Redirecciones innecesarias | Auditar y eliminar cadenas de redirección; implementar HSTS |
| Duración de caché | Arranque lento del service worker | Simplificar el código del service worker; usar estrategias de caché eficientes |
| Duración de DNS | Proveedor DNS lento | Cambiar a un proveedor DNS premium como Cloudflare; ajustar la configuración TTL |
| Duración de conexión | Versión TLS obsoleta | Habilitar TLS 1.3 y HTTP/3; usar un CDN para proximidad |
| Duración de solicitud | Procesamiento lento del servidor | Implementar caché del lado del servidor; optimizar consultas de base de datos; usar 103 Early Hints |
Medir el TTFB con JavaScript
Puede medir el TTFB completo y sus sub-partes directamente en el navegador usando la Navigation Timing API. El siguiente fragmento calcula el TTFB y registra cada sub-parte:
new PerformanceObserver((entryList) => {
const [nav] = entryList.getEntriesByType('navigation');
const activationStart = nav.activationStart || 0;
const ttfb = nav.responseStart - activationStart;
const waitingDuration = (nav.workerStart || nav.fetchStart) - activationStart;
const cacheDuration = nav.domainLookupStart - (nav.workerStart || nav.fetchStart);
const dnsDuration = nav.domainLookupEnd - nav.domainLookupStart;
const connectionDuration = nav.connectEnd - nav.connectStart;
const requestDuration = nav.responseStart - nav.requestStart;
console.log('TTFB:', ttfb.toFixed(0), 'ms');
console.log(' Waiting:', waitingDuration.toFixed(0), 'ms');
console.log(' Cache:', cacheDuration.toFixed(0), 'ms');
console.log(' DNS:', dnsDuration.toFixed(0), 'ms');
console.log(' Connection:', connectionDuration.toFixed(0), 'ms');
console.log(' Request:', requestDuration.toFixed(0), 'ms');
}).observe({
type: 'navigation',
buffered: true
}); Este código proporciona el mismo desglose que herramientas como CoreDash muestran en el panel de atribución del TTFB. Ejecutar este fragmento en la consola del navegador le da una lectura inmediata para una carga de página individual, mientras que las herramientas RUM recopilan estos datos de miles de usuarios reales para producir valores confiables del percentil 75.
Lectura adicional: guías de optimización
Guías relacionadas:
- 103 Early Hints: envíe hints de recursos antes de que la respuesta completa esté lista, permitiendo que el navegador comience a cargar recursos críticos mientras el servidor aún está procesando.
- Configurar Cloudflare para rendimiento: configure el CDN, caché y características de borde de Cloudflare para reducir el TTFB para audiencias globales.
Sub-partes del TTFB: guías completas
Cada sub-parte del Time to First Byte tiene sus propias estrategias de optimización. Comience con la sub-parte que sus datos RUM identifiquen como el cuello de botella:
- Duración de espera: redirecciones, cola del navegador y optimización HSTS.
- Duración de caché: rendimiento del service worker, caché del navegador y bfcache.
- Duración de DNS: selección de proveedor DNS, configuración TTL y dns-prefetch.
- Duración de conexión: handshake TCP, optimización TLS, HTTP/3 y preconnect.
- Duración de solicitud: tiempo de procesamiento del servidor, consultas de base de datos y optimización del backend.
El rendimiento se cae en cuanto dejas de mirar.
Monto el monitoring, los performance budgets y los procesos. Ahí está la diferencia entre un fix y una solución.
Hablemos
