16 métodos para diferir o programar JavaScript
Aprenda cómo diferir y programar JavaScript

¿Por qué diferir o programar JavaScript?
JavaScript puede ralentizar (y lo hará) su sitio web de varias maneras. Esto puede tener todo tipo de impactos negativos en los Core Web Vitals. JavaScript puede competir por recursos de red, puede competir por recursos de CPU (bloquear el hilo principal) e incluso puede bloquear el análisis de una página web. Diferir y programar sus scripts puede mejorar drásticamente los Core Web Vitals.
Última revisión por Arjen Karel en febrero de 2026
Table of Contents!
- ¿Por qué diferir o programar JavaScript?
- ¿Cómo puede el tiempo de JavaScript afectar los Core Web Vitals?
- ¿Cómo elegir el método de diferimiento correcto?
- Método 1: Usar el atributo defer
- Método 2: Usar el atributo async
- Método 3: Usar módulos
- Método 4: Colocar scripts cerca del final de la página
- Método 5: Inyectar scripts
- Método 6: Inyectar scripts en un momento posterior
- Método 7: Cambiar el tipo de script (y luego cambiarlo de nuevo)
- Método 9: Usar readystatechange
- Método 10: Usar setTimeout sin timeout
- Método 11: Usar setTimeout con un timeout
- Método 12: Usar una promesa para establecer una microtask
- Método 13: Usar una microtarea
- Método 14: Usar requestIdleCallback
- Método 15: Usar postTask
- Método 16: Usar scheduler.yield()
Para minimizar los efectos desagradables que JavaScript puede tener en los Core Web Vitals, generalmente es una buena idea especificar cuándo se pone en cola un script para su descarga y programar cuándo puede consumir tiempo de CPU y bloquear el hilo principal.
¿Cómo puede el tiempo de JavaScript afectar los Core Web Vitals?
¿Cómo puede el tiempo de JavaScript afectar los Core Web Vitals? Solo eche un vistazo a este ejemplo de la vida real. La primera página se carga con JavaScript que bloquea el renderizado. Las métricas de pintura, así como el Total Blocking Time, son bastante malos. El segundo ejemplo es de exactamente la misma página pero con el JavaScript diferido. Verá que la imagen del LCP todavía sufrió un gran impacto. El tercer ejemplo tiene el mismo script ejecutado después del evento 'load' de la página y tiene las llamadas a funciones divididas en partes más pequeñas. Este último está pasando los Core Web Vitals con margen de sobra.
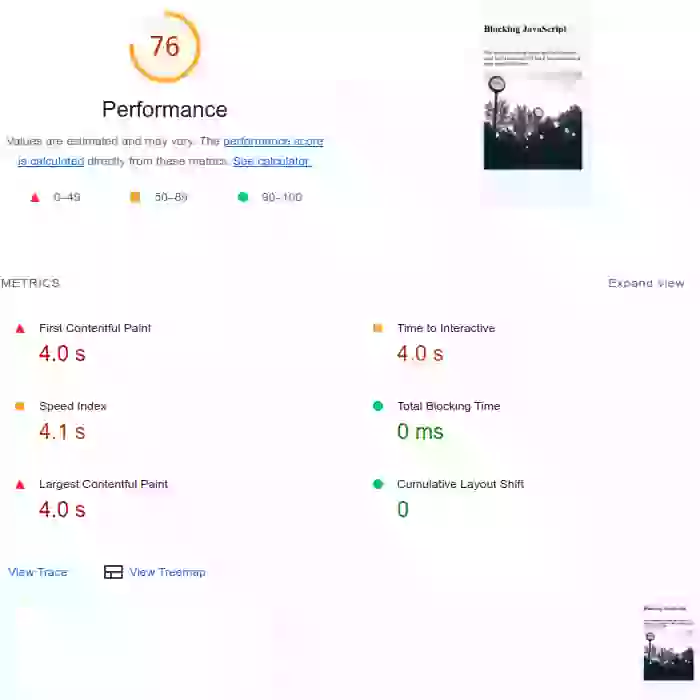

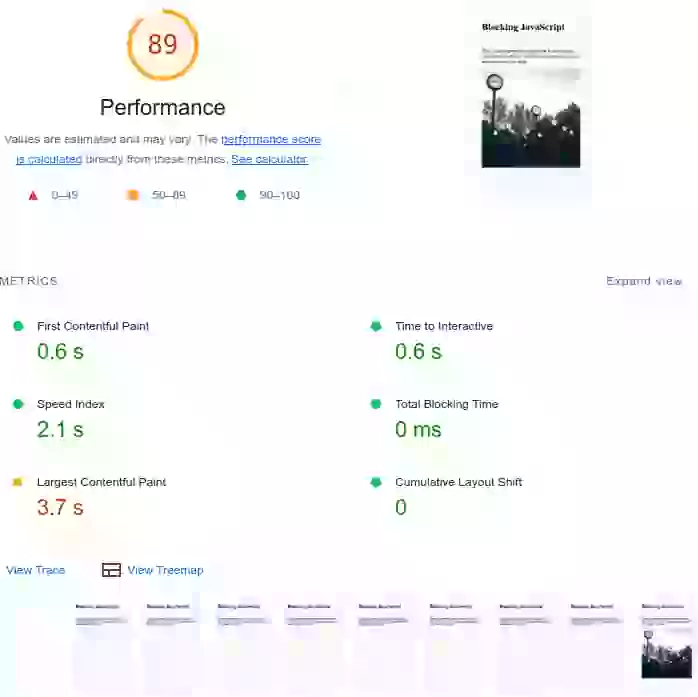
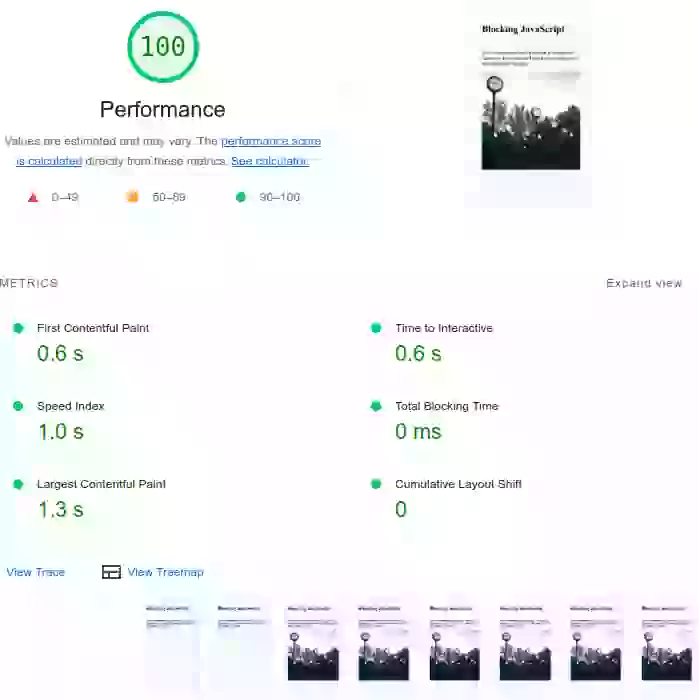
De forma predeterminada, el JavaScript externo en la cabecera de la página bloqueará la creación del árbol de renderizado. Más específicamente: cuando el navegador encuentra un script en el documento, debe pausar la construcción del DOM, ceder el control al entorno de ejecución de JavaScript y dejar que el script se ejecute antes de continuar con la construcción del DOM. Esto afectará a sus Paint Metrics (Largest Contentful Paint y First Contentful Paint).
El JavaScript diferido o async aún puede afectar a las métricas de pintura, especialmente al Largest Contentful Paint porque se ejecutará y bloqueará el hilo principal, una vez que se haya creado el DOM (y es posible que no se hayan descargado los elementos LCP comunes como las imágenes).
Los archivos JavaScript externos también competirán por los recursos de red. Los archivos JavaScript externos generalmente se descargan antes que las imágenes. Si está descargando demasiados scripts, la descarga de sus imágenes se retrasará.
Por último, pero no menos importante, JavaScript podría bloquear o retrasar la interacción del usuario. Cuando un script está utilizando recursos de CPU (bloqueando el hilo principal), un navegador no responderá a las entradas (clics, desplazamiento, etc.) hasta que ese script se haya completado. Esto afecta directamente a su puntuación de Interaction to Next Paint (INP).
El impacto es medible. Según el 2025 Web Almanac, solo el 15% de las páginas móviles aprueban la auditoría de recursos que bloquean el renderizado. La mediana del Total Blocking Time móvil es de 1,916 milisegundos. Eso es casi 2 segundos completos donde el navegador no puede responder a la entrada del usuario. Elegir el método de diferimiento correcto para cada script es la forma de reducir ese número.
¿Cómo soluciona la programación o diferimiento de JavaScript los Core Web Vitals?
Programar o diferir JavaScript no soluciona los Core Web Vitals per se. Se trata de usar la herramienta adecuada para la situación adecuada. Como regla general, debe intentar retrasar sus scripts lo menos posible, pero ponerlos en cola para su descarga y ejecutarlos en el momento adecuado.
¿Cómo elegir el método de diferimiento correcto?
No todos los scripts son iguales y cada script tiene su propia funcionalidad. Algunos scripts son importantes para tenerlos temprano en el proceso de renderizado, otros no.
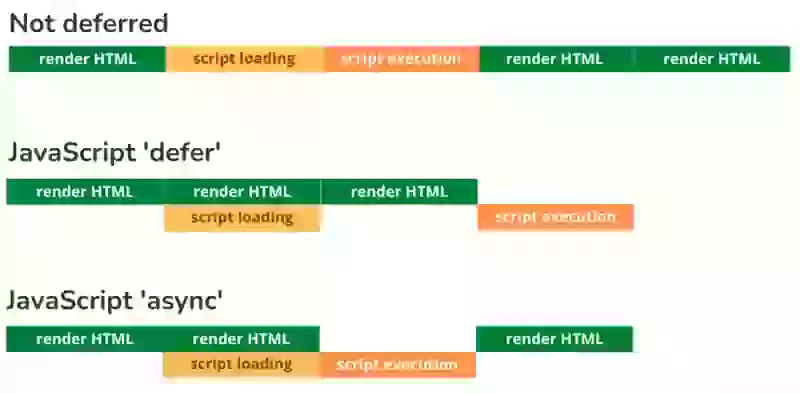
Me gusta categorizar los JavaScripts en 4 grupos según su nivel de importancia.
1. Críticos de renderizado. Estos son los scripts que cambiarán la apariencia de una página web. Si no se cargan, la página no se verá completa. Estos scripts deben evitarse a toda costa. Si no puede evitarlos por alguna razón, no deben diferirse. Por ejemplo, un control deslizante superior o un script de pruebas A/B.
2. Críticos. Estos scripts no cambiarán la apariencia de una página web (demasiado) pero la página no funcionará bien sin ellos. Estos scripts deben ser diferidos o async. Por ejemplo, sus scripts de menú.
3. Importantes. Estos son scripts que desea cargar porque son valiosos para usted o para el visitante. Tiendo a cargar estos scripts después de que el evento de carga (load event) se haya disparado. Por ejemplo, analíticas o un botón de 'volver arriba'.
4. Es bueno tenerlos. Estos son scripts sin los cuales puede vivir si es absolutamente necesario. Cargo estos scripts con la menor prioridad y solo los ejecuto cuando el navegador está inactivo. Por ejemplo, un widget de chat o un botón de facebook.
Método 1: Usar el atributo defer
Los scripts con el atributo defer se descargarán en paralelo y se agregarán a la cola de JavaScript diferido. Justo antes de que el navegador dispare el evento DOMContentLoaded, todos los scripts en esa cola se ejecutarán en el orden en que aparecen en el documento.
<script src='javascript.js'></script> El 'truco defer' generalmente soluciona muchos problemas, especialmente las métricas de pintura. Desafortunadamente no hay garantía, depende de la calidad de los scripts. Los scripts diferidos se ejecutarán una vez que todos los scripts se hayan cargado y el HTML esté analizado (DOMContentLoaded). Es posible que el elemento LCP (generalmente una imagen grande) no se haya cargado para entonces y los scripts diferidos seguirán causando un retraso en el LCP.
Cuándo usar:
Use scripts diferidos para scripts Críticos que se necesiten lo antes posible.
Ventajas:
- Los scripts diferidos se descargarán en paralelo
- El DOM estará disponible en el momento de la ejecución
Desventajas:
- Los scripts diferidos pueden retrasar sus métricas LCP
- Los scripts diferidos bloquearán el hilo principal una vez que se ejecuten
- Puede que no sea seguro diferir scripts cuando scripts inline o async dependen de ellos
Método 2: Usar el atributo async
Los scripts con el atributo async se descargan en paralelo y se ejecutarán inmediatamente después de que hayan terminado de descargarse.
<script src='javascript.js'></script> Los scripts async harán poco para solucionar sus problemas de velocidad de página. Es genial que se descarguen en paralelo, pero eso es todo. Una vez que se descargan, bloquearán el hilo principal a medida que se ejecutan.
Cuándo usar:
Use scripts async para scripts Críticos que se necesiten lo antes posible y sean independientes (no dependan de otros scripts).
Ventajas:
- Los scripts async se descargarán en paralelo.
- Los scripts async se ejecutarán lo antes posible.
Desventajas:
- DOMContentLoaded puede ocurrir tanto antes como después de async.
- El orden de ejecución de los scripts será desconocido de antemano.
- No puede usar scripts async que dependan de otros scripts async o diferidos
Para una comparación detallada de estos dos enfoques, consulte defer vs async y cómo esto afecta los Core Web Vitals.
Método 3: Usar módulos
Los scripts modulares están diferidos de forma predeterminada a menos que tengan el atributo async. En ese caso serán tratados como scripts async
<script src='javascript.js'></script> Los módulos son una nueva forma de pensar sobre JavaScript y solucionan algunos fallos de diseño. Aparte de eso, usar módulos de scripts no acelerará su sitio web.
Cuándo usar:
Cuando su aplicación está construida de forma modular, tiene sentido usar también módulos de JavaScript.
Ventajas:
- Los módulos están diferidos de forma predeterminada
- Los módulos son más fáciles de mantener y funcionan muy bien con el diseño web modular
- Los módulos permiten una fácil división de código con importaciones dinámicas donde solo importa los módulos que necesita en un momento determinado.
Desventajas:
- Los módulos en sí mismos no mejorarán los Core Web Vitals
- Importar módulos justo a tiempo o sobre la marcha puede ser lento y empeorar el INP
Método 4: Colocar scripts cerca del final de la página
Los scripts en el pie de página se ponen en cola para su descarga en un momento posterior. Esto dará prioridad a otros recursos que estén en el documento por encima de la etiqueta de script.
<html>
<head></head>
<body>
[your page contents here]
<script defer src='javascript.js'></script>
</body>
</html> Colocar sus scripts en la parte inferior de la página es una técnica interesante. Esto programará otros recursos (como imágenes) antes de sus scripts. Esto aumentará la posibilidad de que estén disponibles para el navegador y se pinten en la pantalla antes de que los archivos JavaScript hayan terminado de descargarse y el hilo principal sea bloqueado por la ejecución del script. Aun así... no hay garantía.
Cuándo usar:
Cuando sus scripts ya están funcionando bastante bien pero desea priorizar ligeramente otros recursos como imágenes y webfonts.
Ventajas:
- Colocar scripts en la parte inferior de la página no requiere mucho conocimiento.
- Si se hace correctamente, no hay riesgo de que esto rompa su página
Desventajas:
- Los scripts críticos pueden descargarse y ejecutarse más tarde
- No soluciona ningún problema subyacente de JavaScript
Método 5: Inyectar scripts
Los scripts inyectados se tratan como scripts async. Se descargan en paralelo y se ejecutan inmediatamente después de la descarga.
<script>
const loadScript = (scriptSource) => {
const script = document.createElement('script');
script.src = scriptSource;
document.head.appendChild(script);
}
// call the loadscript function that injects 'javascript.js'
loadScript('javascript.js');
</script> Desde la perspectiva de Core Web Vitals, esta técnica es exactamente la misma que usar <script async>.
Cuándo usar:
Este método es a menudo utilizado por scripts de terceros que se disparan lo antes posible. La llamada a la función hace que sea fácil encapsular y comprimir el código.
Ventajas:
- Contenido, código que inyecta un script async.
Desventajas:
- DOMContentLoaded puede ocurrir tanto antes como después de que se haya cargado el script.
- El orden de ejecución de los scripts será desconocido de antemano.
- No puede usar esto en scripts que dependan de otros scripts async o diferidos
Método 6: Inyectar scripts en un momento posterior
En mi opinión, los scripts que son buenos tener nunca deberían cargarse diferidos. Deberían inyectarse en el momento más oportuno. En el ejemplo a continuación, el script se ejecutará después de que el navegador haya enviado el evento 'load'.
<script>
window.addEventListener('load', function () {
// see method 5 for the loadscript function
loadScript('javascript.js');
});
</script> Esta es la primera técnica que mejorará de manera confiable el Largest Contentful Paint. Todos los recursos importantes, incluidas las imágenes, se descargarán cuando el navegador dispare el evento 'load'. Esto podría introducir todo tipo de problemas porque podría llevar mucho tiempo que se llame al evento load.
Cuándo usar:
Para scripts que son buenos tener y que no tienen por qué afectar las métricas de pintura.
Ventajas:
- No competirá por recursos críticos porque inyectará el script una vez que la página y sus recursos se hayan cargado
Desventajas:
- Si su página está mal diseñada en cuanto a Core Web Vitals, podría llevar mucho tiempo para que la página envíe el evento 'load'
- Debe tener cuidado de no aplicar esto a scripts críticos (como lazy loading, menús, etc.)
Método 7: Cambiar el tipo de script (y luego cambiarlo de nuevo)
Si se encuentra una etiqueta de script en algún lugar de la página que 1. tiene un atributo type y 2. el atributo type no es "text/javascript", el script no será descargado ni ejecutado por un navegador. Muchos cargadores de JavaScript (como RocketLoader de CloudFlare) se basan en este principio. La idea es bastante simple y elegante.
Primero todos los scripts se reescriben así:
<script src="javascript.js"></script> Luego, en algún momento durante el proceso de carga, estos scripts se convierten de nuevo a 'javascripts normales'.
Cuándo usar:
Este no es un método que recomendaría. Arreglar el impacto de JavaScript requerirá mucho más que solo mover cada script un poco más abajo en la cola. Por otro lado, si tiene poco control sobre los scripts que se ejecutan en la página o tiene un conocimiento insuficiente de JavaScript, esta podría ser su mejor opción.
Ventajas:
- Es fácil, simplemente habilite rocket loader u otro plugin y todos sus scripts se ejecutan ahora en un momento algo posterior.
- Probablemente solucionará sus métricas de pintura siempre que no haya utilizado lazy loading basado en JS.
- Funcionará para scripts inline y externos.
Desventajas:
- No tendrá un control preciso sobre cuándo se ejecutan los scripts
- Los scripts mal escritos podrían romperse
- Usa JavaScript para arreglar JavaScript
- No hace nada para arreglar los scripts de larga duración
Método 8: Usar el intersection observer
Con el intersection observer puede ejecutar una función (que en este caso carga un JavaScript externo) cuando un elemento se desplaza hacia la ventana gráfica visible (viewport).
<script>
const handleIntersection = (entries, observer) => {
if (entries?.[0].isIntersecting) {
// load your script or execute another
function like trigger a lazy loaded element
loadScript('javascript.js');
// remove the observer
observer.unobserve(entries?.[0].target);
}
};
const Observer = new window.IntersectionObserver()
Observer.observe(document.querySelector('footer'));
</script> Este es, con mucho, el método más eficaz de diferir JavaScript que existe. Solo cargue los scripts que necesita, justo antes de que los necesite. Desafortunadamente, la vida real casi nunca es tan limpia y no muchos scripts se pueden vincular a un elemento que se desplaza a la vista.
Cuándo usar:
¡Use esta técnica tanto como sea posible! Siempre que un script solo interactúe con un componente fuera de la pantalla (como un mapa, un control deslizante, un formulario), esta es la mejor manera de inyectar este script.
Ventajas:
- No interferirá con Core Web Vitals LCP y FCP
- Nunca inyectará scripts que no se utilicen. Esto mejorará el INP
Desventajas:
- No debe usarse con componentes que podrían estar en la ventana gráfica visible
- Es más difícil de mantener que un <script src="..."> básico
- Podría introducir un layout shift
Método 9: Usar readystatechange
document.readystate se puede utilizar como una alternativa al evento 'DOMContentloaded' y 'load'. El readystate 'interactive' suele ser un buen lugar para llamar scripts críticos que necesitan cambiar el DOM o agregar manejadores de eventos.
El readystate 'complete' es un buen lugar para llamar scripts que son menos críticos.
document.addEventListener('readystatechange', (event) => {
if (event.target.readyState === 'interactive') {
initLoader();
} else if (event.target.readyState === 'complete') {
initApp();
}
}); Método 10: Usar setTimeout sin timeout
setTimeout es un método mal visto pero muy subestimado en la comunidad de pagespeed. setTimeout ha ganado mala fama porque a menudo se usa mal. Muchos desarrolladores creen que setTimeout solo se puede usar para retrasar la ejecución del script por la cantidad establecida de milisegundos. Si bien esto es cierto, setTimeout en realidad hace algo mucho más interesante. Crea una nueva tarea al final del bucle de eventos (event loop) del navegador. Este comportamiento se puede utilizar para programar sus tareas de manera efectiva. También se puede utilizar para dividir tareas largas en tareas más pequeñas separadas
<script>
setTimeout(() => {
// load a script or execute another function
console.log('- I am called from a 0ms timeOut()')
}, 0);
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I am called from a 0ms timeOut()
*/
</script> Cuándo usar:
setTimeout crea una nueva tarea en el bucle de eventos del navegador. Úselo cuando su hilo principal esté siendo bloqueado por muchas llamadas a funciones que se ejecutan secuencialmente.
Ventajas:
- Puede dividir el código de larga duración en piezas más pequeñas.
Desventajas:
- setTimeout es un método bastante crudo y no ofrece priorización para scripts importantes.
- Agregará el código a ejecutar al final del bucle
Método 11: Usar setTimeout con un timeout
Las cosas se ponen aún más interesantes cuando llamamos a setTimeout con un timeout de más de 0ms
<script>
setTimeout(() => {
// load a script or execute another function
console.log('- I am called from a 10ms timeOut()')
}, 10);
setTimeout(() => {
// load a script or execute another function
console.log('- I am called from a 0ms timeOut()')
}, 0);
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I am called from a 0ms timeOut()
- I am called from a 10ms timeOut()
*/
</script> Cuándo usar:
Cuando necesite un método fácil para programar un script después de otro, un pequeño timeout hará el truco
Ventajas:
- Compatible con todos los navegadores
Desventajas:
- No ofrece programación avanzada
Método 12: Usar una promesa para establecer una microtask
La creación de una microtarea (microtask) también es una forma interesante de programar JavaScript. Las microtareas están programadas para su ejecución inmediatamente después de que haya finalizado el bucle de ejecución actual.
<script>
const myPromise = new Promise((resolve, reject) => {
resolve();
}).then(
() => {
console.log('- I was scheduled after a promise')
}
);
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I was scheduled after a promise
*/
</script> Cuándo usar:
Cuando una tarea debe programarse inmediatamente después de otra tarea.
Ventajas:
- La microtarea se programará inmediatamente después de que la tarea haya terminado de ejecutarse.
- Se puede usar una microtarea para retrasar fragmentos de código JavaScript menos importantes en el mismo evento.
Desventajas:
- No dividirá el hilo principal en partes más pequeñas. El navegador no tendrá oportunidad de responder a la entrada del usuario.
- Probablemente nunca necesitará usar microtareas para mejorar los Core Web Vitals a menos que ya sepa exactamente lo que está haciendo.
Método 13: Usar una microtarea
El mismo resultado se puede lograr usando queueMicrotask(). La ventaja de usar queueMicrotask() sobre una promesa es que es un poco más rápido y no necesita manejar sus promesas.
<script>
queueMicrotask(() => {
console.log('- I am a microtask')
})
console.log('- I was last in line but executed first')
/*
Output:
- I was last in line but executed first
- I am a microtask
*/
</script> Método 14: Usar requestIdleCallback
El método window.requestIdleCallback() pone en cola una función para ser llamada durante los períodos de inactividad (idle) del navegador. Esto permite a los desarrolladores realizar trabajo en segundo plano y de baja prioridad en el bucle de eventos principal, sin afectar a los eventos críticos para la latencia, como la animación y la respuesta de entrada. Las funciones generalmente se llaman en orden de primero en entrar, primero en salir; sin embargo, los callbacks que tienen un timeout especificado pueden ser llamados fuera de orden si es necesario para ejecutarlos antes de que transcurra el timeout.
<script>
requestIdleCallback(() => {
const script = document.createElement('script');
script.src = 'javascript.js';
document.head.appendChild(script);
});
</script> Cuándo usar:
Use esto para scripts que son Es bueno tenerlos (Nice to have) o para manejar tareas no críticas después de la entrada del usuario
Ventajas:
- Ejecuta JavaScript con un impacto mínimo para el usuario
- Lo más probable es que mejore el INP
Desventajas:
- No hay garantía de que el código se ejecute alguna vez
Método 15: Usar postTask
El método scheduler.postTask() permite a los usuarios especificar opcionalmente un retraso mínimo antes de que se ejecute la tarea, una prioridad para la tarea y una señal que se puede usar para modificar la prioridad de la tarea y/o abortar la tarea. Este devuelve una promesa que se resuelve con el resultado de la función callback de la tarea, o se rechaza con la razón de aborto o un error arrojado en la tarea.
<script>
scheduler.postTask(() => {
const script = document.createElement('script');
script.src = 'javascript.js';
document.head.appendChild(script);
}, { priority: 'background' });
</script> Cuándo usar:
postTask es la API correcta para programar scripts cuando necesita un control preciso sobre la prioridad.
Ventajas:
- ¡Control total sobre la programación de ejecución de JavaScript!
Desventajas:
- No compatible en Safari. Compatible en Chrome 94+, Edge 94+ y Firefox 142+. Use detección de características y un fallback de setTimeout para cobertura completa.
Método 16: Usar scheduler.yield()
scheduler.yield() es la forma más nueva de dividir tareas largas. Devuelve una promesa que se resuelve en una nueva tarea, dando al navegador la oportunidad de responder a la entrada del usuario entre fragmentos de trabajo. A diferencia de setTimeout, la continuación obtiene prioridad sobre otras tareas en cola, por lo que su código continúa donde lo dejó sin ser empujado al final de la línea.
<script>
async function processItems(items) {
for (const item of items) {
doWork(item);
await scheduler.yield();
}
}
</script> Esta es la mejor herramienta individual para mejorar el INP. Las tareas largas que bloquean el hilo principal durante cientos de milisegundos se pueden dividir en partes más pequeñas, cada una separada por un punto de yield. El navegador puede manejar la entrada del usuario en cada punto de yield. Para un recorrido práctico de este patrón, consulte cómo hacer yield al hilo principal.
Safari aún no es compatible con scheduler.yield(), así que siempre incluya un fallback:
<script>
function yieldToMain() {
if (globalThis.scheduler?.yield) {
return scheduler.yield();
}
return new Promise(resolve => {
setTimeout(resolve, 0);
});
}
async function processItems(items) {
for (const item of items) {
doWork(item);
await yieldToMain();
}
}
</script> Cuándo usar:
Use esto siempre que tenga JavaScript de larga duración que bloquee el hilo principal. Es el enfoque recomendado para mejorar el INP en los manejadores de interacción y cualquier código que procese datos en un bucle.
Ventajas:
- Divide tareas largas sin perder su lugar en la cola
- La continuación se ejecuta antes que otras tareas en cola (a diferencia de setTimeout, que va al final de la línea)
- Mejora directamente el INP al darle al navegador la oportunidad de responder a la entrada del usuario
Desventajas:
- No compatible en Safari. Compatible en Chrome 129+, Edge 129+ y Firefox 142+.
- Requiere un fallback para una cobertura completa del navegador (setTimeout funciona como polyfill)
Después de aplicar estas técnicas, verifique la mejora con Real User Monitoring. Las puntuaciones de Lighthouse son un punto de partida, pero los datos de campo de usuarios reales son lo que Google utiliza para el ranking. CoreDash rastrea el INP y todos los Core Web Vitals de visitantes reales, por lo que puede ver si su estrategia de diferimiento realmente está funcionando en producción.
Tiempo real. No medias de 28 días.
CoreDash segmenta cada métrica por ruta, dispositivo, browser y tipo de conexión.
Echa un vistazo a CoreDash
